Learn how to conduct a data readiness assessment for SAP transformation and AI initiatives, with framework, checklist, and automation best practices.
Data Readiness Assessment: A Complete Guide for SAP and Enterprise Transformation Projects
Enterprise transformation projects are rarely limited by technology. More often, they are limited by data.
Whether you are migrating to SAP S/4HANA, consolidating multiple ERP systems, modernizing your integration landscape, or launching AI-driven automation initiatives, one factor determines success more than any other: data readiness.
A structured data readiness assessment ensures that your data is accurate, consistent, harmonized, and technically prepared to support transformation. Without it, even the most well-planned SAP or AI initiative can stall due to poor data quality, broken integrations, or misaligned master data.
In this comprehensive guide, we will cover:
- What a data readiness assessment is
- Why data readiness is critical for SAP and enterprise transformation
- How to build a scalable data readiness framework
- What “data readiness for AI” really means
- How to assess AI data readiness in enterprise landscapes
- A practical data readiness assessment checklist
- Why automation is essential for sustainable readiness
If your organization is preparing for digital transformation, SAP migration, or AI adoption, this guide will help you establish a solid data foundation.
What Is a Data Readiness Assessment?
A data readiness assessment is a structured evaluation of whether an organization’s data is prepared to support a specific business initiative, such as:
- SAP S/4HANA migration
- ERP consolidation
- Cloud transformation
- System integration projects
- AI and automation programs
It evaluates the condition, structure, quality, governance, and technical compatibility of data before it is migrated, integrated, or used to power advanced processes.
At its core, a data readiness assessment answers three critical questions:
- Is our data accurate and complete?
- Is it structured and aligned with target systems?
- Can it reliably support automation and AI initiatives?
Core objectives of a data readiness assessment
A data readiness assessment is a structured evaluation of systemic data risk, structural compatibility, governance maturity, and long-term scalability. The following objectives define a comprehensive and strategically aligned approach to data readiness:
- Quantify data quality risk: The first objective is to measure the actual condition of enterprise data using defined quality metrics, such as completeness, accuracy, consistency, duplication rates, and adherence to validation rules. Instead of relying on assumptions, organizations generate measurable indicators of data health — for example, identifying that a significant percentage of vendor records are duplicated across company codes or that mandatory tax fields are inconsistently populated. Quantifying these risks early allows project teams to estimate remediation effort, anticipate migration challenges, and prevent costly delays during transformation programs.
- Assess structural and semantic alignment: Data readiness requires structural compatibility with target systems, not just clean values. This objective evaluates whether source data aligns with the technical and semantic requirements of the future architecture, including field lengths, data types, mapping logic, and business definitions. For instance, inconsistencies in product classification structures or differing interpretations of key fields, such as “Customer Type”, across systems can create serious integration and reporting issues. Identifying these misalignments during assessment prevents transformation failures caused by incompatible data models.
- Evaluate master data integrity and governance maturity: Master data integrity is essential for operational stability, and this objective examines both the technical consistency and governance structures surrounding critical data objects. It includes detecting fragmented customer or vendor records, inconsistent hierarchies, and unclear data ownership models. For example, if vendor master data lacks defined stewardship, duplicate or obsolete records will continue to accumulate, even after cleansing efforts. Sustainable enterprise data readiness requires not only harmonized master data but also clearly defined accountability and validation processes.
- Analyze integration dependencies and data flow stability: Enterprise data exists within interconnected system landscapes, making integration stability a core objective of data readiness. This involves mapping upstream and downstream dependencies, assessing transformation logic within interfaces, and evaluating synchronization mechanisms across systems. A structural change in material master data, for example, may unintentionally disrupt downstream warehouse or E-commerce platforms if dependencies are not fully understood. By analyzing data flow stability, organizations ensure that transformation initiatives do not compromise operational continuity.
- Determine migration feasibility and remediation effort: A data readiness assessment must translate identified gaps into realistic remediation planning. This includes defining archiving strategies, estimating cleansing workload, prioritizing critical data objects, and evaluating automation opportunities. For example, determining that a substantial portion of historical transactional data can be archived instead of migrated may significantly reduce project complexity and cost. By quantifying remediation effort, organizations can align budgets, timelines, and resource planning with actual data conditions.
- Validate scalability for AI and automation initiatives: Modern transformation strategies increasingly depend on intelligent automation and AI-driven processes, making scalability a critical objective of data readiness. This involves evaluating whether data is standardized, traceable, harmonized, and supported by automated validation mechanisms. For instance, inconsistent product hierarchies or fragmented customer records can undermine AI-based forecasting or automated workflows. Ensuring data readiness for AI requires preparing enterprise data not only for migration but also for sustained automation at scale.
- Establish a baseline for continuous data excellence: Finally, a comprehensive data readiness assessment establishes measurable benchmarks that support ongoing monitoring and improvement. By defining key quality indicators, validation rules, and governance checkpoints, organizations can shift from one-time corrective efforts to continuous data management. For example, automated monitoring of duplication rates or completeness thresholds ensures that improvements achieved during transformation are maintained long after go-live. This transforms data readiness from a temporary project requirement into a permanent enterprise capability.
Together, these objectives position a data readiness assessment as a strategic instrument that reduces uncertainty, mitigates transformation risk, and prepares enterprise data for long-term operational and AI-driven evolution.
When Is a Data Readiness Assessment Required?
A data readiness assessment is often associated with large-scale system migrations. In reality, it becomes essential whenever enterprise data is expected to support structural change, operational redesign, or intelligent automation. Any initiative that alters systems, processes, or decision-making logic inevitably exposes weaknesses in underlying data. Conducting a structured assessment at the right time allows organizations to identify hidden risks before they appear as project delays, reconciliation failures, or automation breakdowns.
Below are the most common scenarios where a data readiness assessment is not just beneficial, but critical.
SAP S/4HANA migration or ERP modernization
A migration to SAP S/4HANA fundamentally changes the technical and functional data model of the enterprise. Legacy ERP systems often contain years — sometimes decades — of accumulated inconsistencies, unused custom fields, duplicate master records, and workarounds that were implemented to compensate for earlier limitations.
When organizations move to S/4HANA, these legacy artifacts do not automatically resolve themselves. Instead, they surface during data load testing, reconciliation cycles, or post-go-live operations. For example, inconsistent material master hierarchies can disrupt procurement workflows, and incomplete financial master data can lead to reporting discrepancies after cutover.
A data readiness assessment before migration helps organizations decide what should be cleansed, harmonized, archived, or excluded. Rather than transferring historical inefficiencies into a modern platform, enterprises can use the transition as an opportunity to standardize and simplify their data landscape.
ERP consolidation or multi-system harmonization
When companies merge, acquire new entities, or consolidate multiple ERP systems into a single global template, they encounter structural and semantic conflicts across datasets. Different business units may use disparate naming conventions, classification structures, or coding standards for the same objects.
For example, one subsidiary may categorize products using a region-specific taxonomy, while another applies a global standard. Vendor identifiers may overlap between systems, or financial account structures may differ significantly. Without harmonization, consolidation creates duplication, reporting inconsistencies, and operational confusion.
A data readiness assessment in this context focuses on structural alignment and cross-system compatibility. It identifies conflicts in master data, reconciles semantic differences, and defines harmonization strategies before integration begins. This proactive approach prevents systemic inconsistencies from becoming embedded in the consolidated environment.
Cloud migration and platform modernization
Moving enterprise systems or integration layers to the cloud introduces new architectural requirements. Cloud platforms often enforce stricter data format standards, API-based integration patterns, and real-time synchronization mechanisms. Legacy systems, however, frequently rely on batch processes, loosely structured fields, or undocumented transformation logic.
If these inconsistencies are not assessed beforehand, migration to the cloud may amplify data errors rather than resolve them. For example, poorly standardized customer address data may cause failures in API validation rules, or inconsistent product codes may break automated integration pipelines.
A data readiness assessment in cloud transformation initiatives evaluates data quality, as well as structural compatibility and integration resilience. It ensures that data can move reliably through modern architectures without constant manual intervention.
Business process redesign and automation initiatives
Enterprise transformation often involves redesigning business processes to increase efficiency, standardize operations, or introduce automation. However, process automation depends on structured, consistent, and reliable data inputs.
For instance, automating purchase order approvals requires standardized supplier classifications and complete master data. Introducing automated inventory planning requires harmonized material master data and accurate historical transaction records. If these foundational elements are inconsistent, automation logic produces unreliable outcomes.
A data readiness assessment before automation initiatives helps organizations validate that their data can support new process logic. It identifies gaps in classification structures, missing attributes, or inconsistent validation rules that could undermine automated workflows.
AI and advanced analytics programs
The introduction of AI-driven capabilities places even greater demands on enterprise data. While traditional reporting systems may tolerate minor inconsistencies, AI models amplify errors and inconsistencies in training data.
For example, inconsistent product categorization across regions can distort forecasting outputs. Duplicate customer records may skew predictive churn models. Incomplete historical data may reduce the reliability of demand planning algorithms.
Data readiness for AI requires a higher standard of consistency, traceability, and standardization than most legacy environments provide. A data readiness assessment ensures that master data is harmonized, validation rules are automated, and integration pipelines are stable before AI models are deployed. Without this foundation, AI initiatives risk producing misleading or unstable results.
Post-merger integration or organizational restructuring
After mergers, acquisitions, or structural reorganizations, enterprise data landscapes become fragmented. Newly combined entities may operate on different ERP systems, follow distinct governance models, and apply divergent data standards.
In these situations, reporting inconsistencies often become the first visible symptom of deeper data misalignment. However, the root cause typically lies in incompatible master data definitions, conflicting hierarchies, or unclear data ownership.
Conducting a data readiness assessment during post-merger integration helps organizations align definitions, standardize data objects, and establish unified governance structures. This ensures that strategic decisions are based on consistent and trustworthy information.
Continuous data governance maturity programs
Finally, a data readiness assessment is not limited to transformation milestones. Mature organizations incorporate periodic assessments into their data governance strategies to monitor ongoing data health.
Rather than reacting to issues during major projects, enterprises can proactively measure duplication rates, completeness thresholds, and validation compliance over time. This transforms readiness from a reactive project task into a continuous improvement capability.
In essence, a data readiness assessment becomes necessary whenever enterprise data is expected to support change. The greater the transformation, the more critical it becomes to validate the strength and stability of the data foundation. Conducted at the right time, a data readiness assessment prevents hidden risks from surfacing at the most disruptive moments and enables transformation initiatives to proceed with clarity and confidence.
Why Data Readiness Assessment Is Critical for SAP Transformation
SAP transformation initiatives (e.g., transitioning to SAP S/4HANA, redesigning core processes, or consolidating global ERP instances) fundamentally depend on the integrity and structural consistency of enterprise data. Unlike loosely coupled systems, SAP environments are tightly integrated and process-driven. Master and transactional data flow across finance, supply chain, procurement, manufacturing, and sales in a highly interdependent manner.
If underlying data is incomplete, duplicated, semantically inconsistent, or structurally misaligned, system configuration alone cannot compensate. Even technically flawless implementations can fail operationally when data quality gaps surface during migration, testing, or post-go-live stabilization.
A structured data readiness assessment mitigates these risks by validating data condition, compatibility, and governance maturity before transformation reaches critical execution phases.
The cost of poor data readiness in SAP projects
Data-related failures in SAP projects rarely appear in early planning stages. They typically emerge during integration testing, mock loads, reconciliation cycles, or — most disruptively — after go-live. By that stage, remediation becomes significantly more complex and expensive.
Common consequences of insufficient data readiness include:
- Migration load failures caused by missing mandatory fields or incompatible formats
- Financial reconciliation mismatches between legacy and target systems
- Duplicate business partner records after customer–vendor integration
- Broken cross-module dependencies due to inconsistent master data
- Delayed cutover timelines caused by urgent cleansing efforts
For example, during an S/4HANA migration, legacy customer master records may lack mandatory tax classifications or standardized address formats required by the target system. These gaps may not surface until load validation begins, forcing emergency remediation cycles that affect project timelines and stakeholder confidence.
More critically, data inconsistencies in SAP environments often cascade across modules. An incorrect material classification can simultaneously affect pricing conditions, Material Requirements Planning logic, warehouse processes, and financial reporting. What appears to be a localized issue may quickly become a systemic disruption.
A data readiness assessment addresses these risks proactively by quantifying data gaps, identifying structural misalignment, and estimating remediation effort before transformation execution accelerates.
Data readiness in S/4HANA and Clean Core strategies
The transition to SAP S/4HANA introduces a simplified data model and promotes Clean Core principles that emphasize standardization and reduced customization. While these changes offer performance and maintainability benefits, they also expose legacy inconsistencies that older systems may have tolerated.
Many SAP ECC environments have evolved through years of regional customization, temporary fixes, and evolving business requirements. As a result, they frequently contain:
- Obsolete custom fields
- Redundant or inactive master data records
- Inconsistent classification structures across company codes
- Historical transactional data with limited operational value
- Divergent data definitions across business units
S/4HANA’s unified data structures (e.g., Business Partner integration and the Universal Journal) require higher levels of harmonization and consistency. Legacy data that was technically valid in ECC may not align with simplified S/4HANA models.
Without a comprehensive data readiness assessment, organizations risk migrating structural inefficiencies into a modernized environment, undermining the objectives of simplification and Clean Core compliance.
By contrast, a structured assessment enables enterprises to:
- Identify obsolete or redundant data before migration
- Harmonize master data across organizational boundaries
- Align field structures with S/4HANA requirements
- Define archiving strategies for non-essential historical records
- Support Clean Core initiatives by minimizing unnecessary extensions
Rather than treating SAP transformation as just a technical migration, organizations can leverage it as an opportunity to elevate enterprise data standards and strengthen long-term governance.
Core Components of a Data Readiness Assessment Framework
A comprehensive data readiness assessment requires more than surface-level profiling or ad hoc validation checks. It must follow a structured framework that evaluates data across technical, structural, operational, and governance dimensions. Without such a framework, organizations risk overlooking hidden dependencies or underestimating remediation effort.
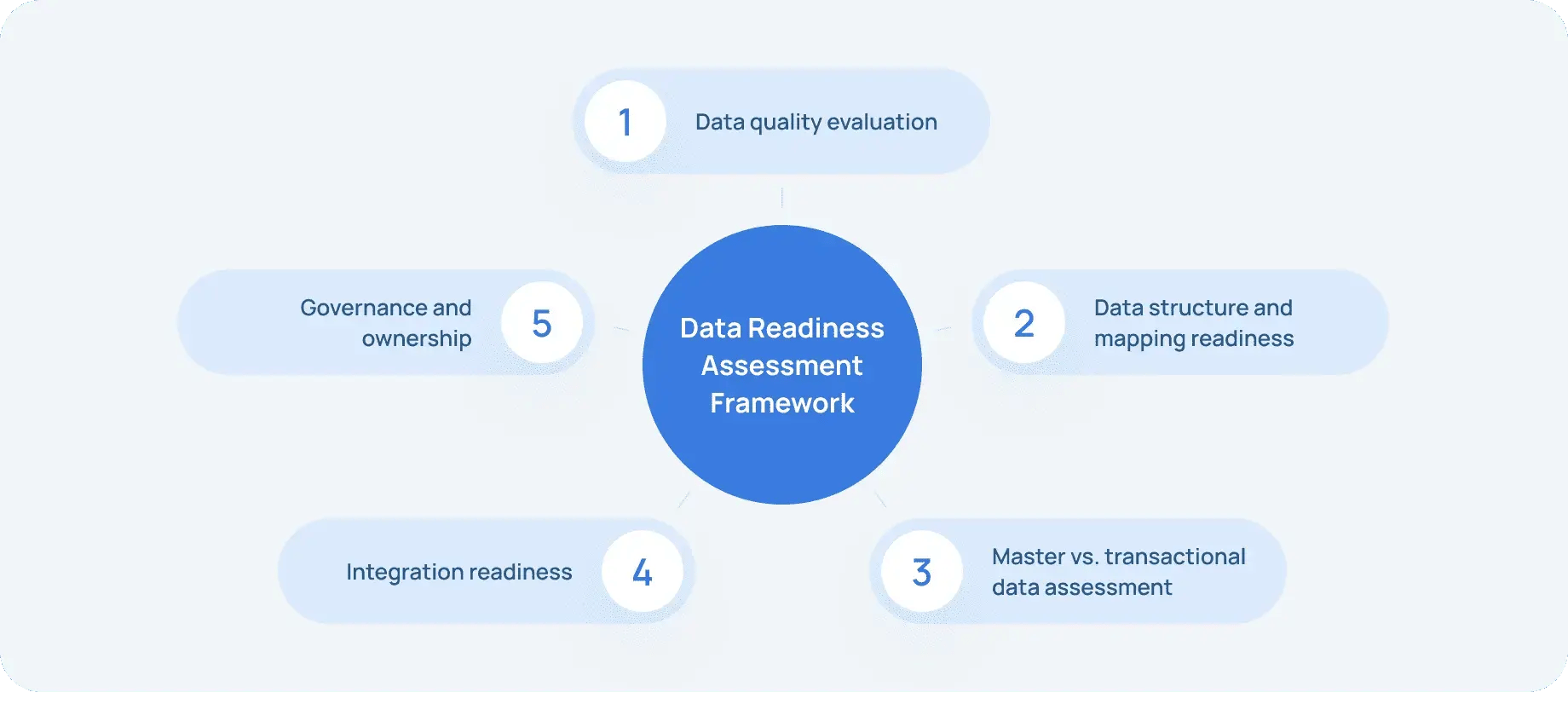
The following steps form the foundation of a robust and scalable data readiness assessment framework.
Step #1: Data quality evaluation
Data quality evaluation is the most visible — yet often the most underestimated — component of a data readiness assessment. While organizations may assume their data is “generally reliable,” structured profiling frequently reveals systemic inconsistencies accumulated over time.
A rigorous evaluation measures core quality dimensions, such as:
- Accuracy: Are data values correct and validated against defined rules?
- Completeness: Are mandatory and business-critical fields populated consistently?
- Consistency: Are definitions and formats standardized across systems and company codes?
- Validity: Do entries conform to business logic and regulatory requirements?
- Uniqueness: Are duplicate records present across organizational entities?
In SAP environments, this may involve identifying duplicate Business Partner records, incomplete material master classifications, inconsistent units of measure, or financial master data discrepancies that could affect reporting integrity.
Importantly, data quality evaluation should produce measurable metrics. Quantified insights allow organizations to prioritize remediation efforts, allocate resources realistically, and assess migration risk with precision.
Step #2: Data structure and mapping readiness
High-quality data alone is insufficient, if it cannot align structurally with the target system. Data structure and mapping readiness focus on compatibility between source and destination environments.
This component evaluates:
- Field-level alignment between legacy and target systems
- Data type compatibility and format constraints
- Code list harmonization
- Transformation logic complexity
- Custom field rationalization
For example, legacy systems may use region-specific material numbering schemes or non-standard classification codes that do not directly align with SAP best practices. Additionally, when compared to ECC, certain fields may have expanded length or changed semantic meaning in S/4HANA.
Mapping readiness also includes assessing whether transformation rules are clearly documented, validated, and testable. Ambiguous mapping logic increases the risk of load failures and post-migration inconsistencies.
By analyzing structural alignment early, organizations prevent technical incompatibilities from disrupting migration cycles and integration testing.
Step #3: Master vs. transactional data assessment
Master data and transactional data play fundamentally different roles in enterprise systems; each requires a distinct evaluation approach within the data readiness framework.
Master data readiness
Master data underpins operational processes. It defines customers, vendors, materials, chart of accounts, and organizational structures. Poor master data quality can destabilize entire workflows.
Assessment activities include:
- Detecting duplicate or fragmented master records
- Validating hierarchy consistency (e.g., product or customer hierarchies)
- Standardizing naming conventions and classifications
- Confirming alignment across regions and business units
- Identifying inactive or obsolete master records
For example, inconsistent vendor master records across company codes may lead to payment errors or compliance risks. Similarly, fragmented product hierarchies can distort procurement planning and inventory management.
Master data readiness must ensure harmonization and structural stability before transformation begins.
Transactional data readiness
Transactional data requires a different lens. Rather than focusing primarily on duplication or classification, the emphasis is on volume, historical relevance, and reconciliation integrity.
Key assessment areas include:
- Evaluating data volumes and performance implications
- Identifying obsolete or low-value historical transactions
- Determining archiving vs. migration criteria
- Validating financial balances and period alignment
- Ensuring consistency between sub-ledgers and general ledger
For example, migrating decades of transactional history without strategic filtering may significantly increase project complexity and system load times. A structured readiness assessment helps define which historical data must be preserved and which can be archived.
By distinguishing between master and transactional data readiness, organizations avoid overcomplicating migration scope while preserving operational continuity.
Step #4: Integration readiness
Modern enterprise landscapes are highly interconnected, and SAP rarely operates in isolation. Data flows continuously between ERP systems, external platforms, cloud applications, and industry-specific solutions.
Integration readiness evaluates:
- Upstream and downstream system dependencies
- Real-time vs. batch synchronization mechanisms
- API and interface compatibility
- Embedded transformation logic within middleware
- Error-handling and reconciliation processes
For example, modifying material master structures during transformation may impact warehouse systems, E-commerce platforms, or reporting tools that rely on specific field formats. Without understanding these dependencies, organizations risk disrupting critical operations.
Integration readiness ensures that transformation does not compromise data flow stability and that cross-system dependencies are proactively managed.
Step #5: Governance and ownership
Technical data improvements are unsustainable without governance structures that define accountability and enforce standards.
This component of the framework examines:
- Defined data ownership roles
- Stewardship responsibilities
- Validation rule enforcement
- Change management processes
- Compliance monitoring mechanisms
For example, if no business function is responsible for maintaining customer master integrity, duplication will inevitably reoccur after cleansing. Similarly, without documented validation rules, data inconsistencies may re-enter the system during routine operations.
Governance and ownership transform data readiness from a one-time project milestone into a sustained organizational capability. They ensure that improvements achieved during transformation persist long after go-live.
Together, these core components form a comprehensive data readiness assessment framework. By evaluating data quality, structural compatibility, master and transactional integrity, integration stability, and governance maturity, organizations gain a multidimensional understanding of their data landscape. This holistic approach reduces transformation risk and establishes a durable foundation for SAP modernization and future AI-driven initiatives.
Data Readiness for AI
While data readiness assessments have traditionally been associated with system migration and ERP transformation, the rise of intelligent automation and AI-driven processes has expanded their scope. Today, organizations must ensure not only that their data can move successfully between systems, but that it can reliably power advanced technologies.
In this context, data readiness for AI builds upon traditional readiness principles, but raises the bar for consistency, standardization, and scalability.
Migration-focused assessments typically concentrate on field compatibility, completeness, and reconciliation accuracy. AI data readiness requires additional characteristics:
- Harmonized master data across regions and business units
- Standardized classifications and taxonomies
- Low duplication rates
- Traceable data lineage
- Stable and automated integration pipelines
AI systems amplify inconsistencies. For example, fragmented customer records across systems may distort predictive models, while inconsistent product classifications can reduce the reliability of automated planning or intelligent workflows. Unlike traditional reporting tools, AI-driven processes are highly sensitive to subtle variations in structure and labeling.
This does not mean that organizations must implement complex AI-specific validation frameworks at the outset of transformation. Rather, it underscores the importance of strengthening core data fundamentals during SAP and enterprise modernization efforts. Clean master data, consistent structures, and governed validation rules are prerequisites for both migration success and future automation initiatives.
In practice, many indicators of AI data readiness overlap with strong enterprise data management principles. These include:
- Consistently defined and governed master data
- Clearly assigned ownership and stewardship
- Automated validation and monitoring mechanisms
- Integrated data flows without manual reconciliation dependencies
By embedding these capabilities into a structured data readiness assessment, organizations prepare for both immediate transformation milestones and for scalable innovation.
In short, data readiness for AI is a natural extension of disciplined enterprise data management. When foundational data standards are established during SAP transformation, organizations create the conditions necessary for intelligent automation to deliver reliable and sustainable value.
Manual vs. Automated Data Readiness Assessment
Many organizations initiate a data readiness assessment using manual techniques, such as spreadsheets, ad hoc SQL queries, exported reports, and workshop-based validations. While these methods may provide preliminary visibility into obvious inconsistencies, they rarely scale to the complexity of modern SAP environments and enterprise transformation programs.
As data landscapes become more interconnected and transformation initiatives more ambitious, the limitations of manual readiness approaches become increasingly apparent. In contrast, automation introduces consistency, repeatability, and long-term control.
Limitations of manual approaches
Manual data readiness assessments typically rely on fragmented analysis and one-time data extracts. Although useful in early exploration phases, they introduce several structural weaknesses:
- Time-intensive and resource-heavy: Profiling large volumes of master and transactional data across multiple systems requires repetitive queries, manual reconciliation, and cross-functional coordination. As data volume and system complexity increase, the effort required grows exponentially, often overwhelming project timelines.
- Static snapshot instead of continuous validation: Manual assessments reflect the state of data at a single point in time. However, enterprise data continues to change throughout transformation. New master records are created, updates are applied, and configuration adjustments occur. Without automated revalidation, previously resolved issues may reappear, and new inconsistencies may go undetected until late testing stages.
- High risk of human error and inconsistent interpretation: Different analysts may apply validation rules inconsistently, leading to conflicting conclusions about data quality. Business logic may be interpreted differently across regions or teams, reducing reproducibility and auditability. Manual processes inherently lack standardized enforcement mechanisms.
- Limited scalability across global SAP landscapes: In multi-entity environments with numerous company codes, plants, and integration touchpoints, maintaining consistent manual validation standards becomes impractical. Ensuring alignment across global teams requires extensive coordination and documentation, which increases operational friction.
- Reactive rather than preventive control: Manual assessments often identify issues after they have already impacted migration cycles or integration testing. Without embedded monitoring mechanisms, organizations remain in a reactive mode, continuously correcting rather than proactively preventing data defects.
These limitations make manual approaches insufficient for complex SAP transformation initiatives where consistency and repeatability are critical.
Benefits of automation
Automated data readiness assessment elevates readiness from a one-time diagnostic task to a structured and repeatable capability embedded within the transformation lifecycle.
By codifying validation rules and applying them systematically across full datasets, automation ensures consistency and transparency. Duplicate detection algorithms, structural compatibility checks, and rule-based validations can be executed repeatedly throughout migration waves, providing real-time insight into remediation progress.
In SAP transformation contexts, automation enables organizations to:
- Perform repeated mock loads with consistent validation logic.
- Monitor master data harmonization progress across regions.
- Enforce standardized mapping and transformation rules.
- Detect structural incompatibilities before integration testing.
- Maintain auditability and traceability of data corrections.
Most importantly, automation extends beyond migration. Once validation frameworks are established, they can remain active post-go-live, supporting governance initiatives and strengthening long-term data readiness for AI and intelligent automation.
Automation does not replace expertise; it amplifies it. By reducing repetitive manual checks, expert teams can focus on resolving structural issues, refining governance models, and strategically improving enterprise data quality.
In strategic terms, the difference between manual and automated data readiness assessment lies in sustainability. Manual methods provide temporary visibility. Automated approaches ensure durable control, scalability, and resilience — essential qualities for modern SAP and enterprise transformation programs.
Data Readiness Assessment Checklist for SAP and AI Initiatives
While the data readiness framework defines what must be evaluated, transformation teams need a practical execution checklist to ensure readiness activities are embedded into project delivery.
While the checklist below is designed for SAP transformation initiatives, it also supports foundational AI data readiness:
1. Define scope and data migration strategy:
- Confirm which systems are in scope for migration or consolidation.
- Identify which data objects will be migrated, archived, or excluded.
- Establish clear migration waves and sequencing.
- Align data scope decisions with business priorities.
Clarity on scope prevents over-migration, reduces unnecessary cleansing effort, and avoids late-stage project expansion.
2. Establish measurable readiness criteria:
- Define quantitative acceptance thresholds (e.g., maximum duplication rates, required completeness levels).
- Align readiness KPIs with business and compliance requirements.
- Agree on go/no-go criteria for mock loads and cutover.
Without clearly defined benchmarks, readiness becomes subjective and difficult to govern.
3. Execute iterative data validation cycles:
- Perform repeated validation before each mock migration.
- Track remediation progress across cycles.
- Re-test previously corrected datasets.
- Ensure consistency between test and production environments.
Iterative validation prevents recurring defects from resurfacing late in the project.
4. Align data readiness with cutover planning:
- Synchronize final data cleansing with cutover timelines.
- Freeze critical master data at defined milestones.
- Confirm reconciliation procedures between legacy and target systems.
- Validate rollback and contingency plans.
Data readiness must be operationally aligned with cutover, rather than treated as a parallel activity.
5. Document transformation logic and data decisions:
- Record mapping rules and transformation assumptions.
- Maintain traceability of data adjustments.
- Ensure documentation supports audit and compliance requirements.
- Create knowledge transfer materials for post-go-live support.
Clear documentation prevents loss of institutional knowledge and supports long-term governance.
6. Validate integration stability before go-live:
- Test interfaces with production-like datasets.
- Confirm synchronization timing and reconciliation mechanisms.
- Simulate real-world transaction flows.
- Validate error-handling scenarios.
Readiness must include interface stability, not just successful data loading.
7. Embed continuous monitoring post-go-live:
- Activate automated validation controls where possible.
- Monitor high-risk data objects after cutover.
- Establish escalation paths for recurring data issues.
- Transition readiness governance into steady-state operations.
This step ensures that data readiness evolves into sustainable data management rather than ending at go-live.
8. Confirm foundational conditions for AI scalability:
- Verify harmonized master data across business units.
- Ensure standardized classification structures.
- Confirm automated validation processes are in place.
- Validate that integration architecture can support near-real-time data flows.
These conditions create the baseline for future AI-driven automation without requiring a separate AI readiness program at this stage.
Making the checklist actionable
A data readiness assessment checklist is only effective when integrated into transformation governance and project planning. Each checkpoint should have:
- Assigned ownership
- Defined timelines
- Measurable outcomes
- Clear escalation paths
For SAP and enterprise transformation programs, this structured approach reduces uncertainty, prevents late-stage surprises, and strengthens long-term enterprise data readiness. By embedding these checks into project execution, organizations build migration confidence and the structural foundation required for scalable automation and AI-driven innovation.
Conclusion
A successful SAP or enterprise transformation is never just a system upgrade; it is a data transformation initiative at its core. Infrastructure can be modernized and processes redesigned, but without a structured data readiness assessment, organizations risk transferring legacy inconsistencies into new architectures.
As this guide has outlined, data readiness is multidimensional. It requires measurable quality validation, structural alignment with target systems, master data harmonization, integration stability, governance accountability, and operational synchronization with migration cycles. When approached systematically, a data readiness assessment reduces uncertainty, clarifies remediation effort, and strengthens cutover confidence.
At the same time, transformation programs must increasingly account for long-term scalability. Establishing strong data foundations during SAP modernization ensures a smooth migration and creates the structural conditions required for intelligent automation and sustainable AI data readiness. Clean, harmonized, and governed data is not only migration-ready; it is innovation-ready.
Organizations that treat data readiness as a strategic discipline — rather than a late-stage technical task — consistently experience lower transformation risk, fewer post-go-live disruptions, and greater agility in adopting new technologies.
If your organization is preparing for SAP S/4HANA migration, ERP consolidation, integration modernization, or automation initiatives, a structured and automated approach to data readiness can significantly reduce project complexity.
DataLark supports enterprises in operationalizing data readiness assessment at scale — enabling automated validation, structured harmonization, and repeatable data controls across SAP landscapes. By embedding readiness into transformation workflows, organizations can move beyond reactive data cleansing and establish a durable foundation for modernization and AI-driven growth.
To learn how DataLark can support your SAP transformation strategy, explore our approach to automated data integration and quality management, and turn data readiness into a measurable competitive advantage.