Long-term sustainabilityExplore common SAP data extraction approaches, key challenges, and what to consider when designing a scalable, enterprise-ready extraction layer.
SAP Data Extraction Tools: How to Reliably Extract SAP Data at Scale
SAP systems sit at the heart of many enterprise landscapes. They run core business processes across finance, supply chain, manufacturing, HR, and more. At the same time, organizations increasingly rely on SAP data outside the SAP ecosystem: in cloud data warehouses, data lakes, operational applications, and AI-driven workflows.
This growing demand has made SAP data extraction tools a critical part of modern data architectures. Yet extracting data from SAP remains one of the most complex and risk-prone integration challenges that enterprises face.
This article explores what SAP data extraction really involves, why it is uniquely difficult, common approaches organizations take, and how to choose a solution that works reliably at scale.
What “SAP Data Extraction” Really Means (and What It Doesn’t)
SAP data extraction is often treated as a technical formality — something that needs to be done so that reporting or analytics can begin. In reality, it plays a much more foundational role. How SAP data is extracted determines whether it can even be used reliably outside of SAP.
In general, SAP data extraction is the act of making SAP data available beyond the SAP system. At its core, SAP data extraction refers to the process of:
- Accessing data stored in SAP systems (such as SAP ECC or SAP S/4HANA)
- Selecting relevant business data (e.g., tables, views, objects, or business entities)
- Transferring that data to external systems
- Preserving structure, consistency, and change history
The key point here is that the goal is not simply to move data, but to do so consistently and predictably.
What is often overlooked is that SAP data extraction is rarely a one-time activity. In most organizations, it is a continuous process. SAP systems are constantly changing as transactions are created, updated, and reversed. To remain useful, extracted data must reflect those changes over time. This makes extraction an operational concern rather than a simple export task.
The data produced through this process typically serves many purposes at once. It may be consumed by data warehouses, data lakes, operational applications, or advanced automation initiatives. In practice, this means that SAP data extraction sits upstream of a wide range of business-critical systems. Any issues introduced at this stage tend to ripple outward, affecting everything that depends on the data later on.
It is also important to be clear about what SAP data extraction is not. Extraction does not include reporting, dashboards, or analytics. It does not define KPIs or interpret business meaning. Those activities belong to downstream layers that assume data is already available, complete, and trustworthy. Treating extraction as part of analytics often leads to unrealistic expectations of the tools involved.
A more accurate way to think about SAP data extraction is as data infrastructure. Its purpose is to move data out of a transactional system and into environments where it can be used in many different ways, without forcing each downstream consumer to solve the same problems repeatedly. When extraction is handled well, it becomes largely invisible — not because it is unimportant, but because it works reliably.
Understanding this distinction is essential when evaluating SAP data extraction tools. The objective is to ensure that SAP data is consistently available and ready for whatever comes next, not to produce insights directly from SAP.
Why Extracting Data from SAP Is Uniquely Difficult
At first glance, SAP is just another source system. It stores data in tables, exposes interfaces, and supports integration. Yet, teams that have worked with SAP data quickly learn that reliably extracting it is very different from pulling data out of most other enterprise systems. What looks straightforward in theory often becomes complex once real business volumes, performance constraints, and change tracking enter the picture.
The difficulty does not come from a single issue, but from a combination of characteristics that are specific to SAP environments:
- SAP data models are designed for transactions, not extraction: SAP systems prioritize transactional integrity and performance for business users. As a result, business objects (e.g., sales orders, invoices, or material movements) are often spread across many interrelated tables. Understanding how those tables fit together and extracting them in a way that preserves business meaning requires SAP-specific knowledge. In real projects, teams frequently discover that extracting “one object” actually means coordinating data from dozens of tables.
- Productive SAP systems are highly sensitive to extraction load: Unlike modern SaaS applications, SAP systems often run core business processes with little tolerance for disruption. Poorly designed extraction jobs can compete with users for system resources, slow down critical transactions, or even trigger system alerts. Many organizations learn this the hard way when an extraction that works in testing causes performance issues in production, forcing teams to redesign jobs around narrow time windows or strict load limits.
- Tracking changes over time is inherently complex: Most SAP data extraction use cases require more than periodic full loads. Businesses need to capture inserts, updates, and deletions as they happen. In practice, not all SAP tables provide clean delta indicators, and update patterns vary widely across modules. For example, a record may be technically “updated” even when its business meaning has not changed, or vice versa. Designing reliable change data capture logic that reflects real business changes is a recurring challenge in SAP environments.
- Business logic is often embedded in SAP, not the database: In many cases, the data that matters most is not stored in a single, ready-to-use form. Key calculations, validations, and transformations may be implemented in ABAP programs or application logic rather than exposed directly in tables. Teams extracting SAP data frequently encounter situations where raw tables alone are insufficient, and additional context is required to make the data usable outside SAP.
- Extraction failures are not always obvious: One of the most problematic aspects of SAP data extraction is that errors can be subtle. A job may be completed successfully from a technical standpoint while still producing incomplete or inconsistent data. Missing records, broken relationships, or partial updates may go unnoticed until downstream reports or applications start producing incorrect results. By that point, tracing the issue back to extraction can be difficult and time-consuming.
Taken together, these challenges explain why SAP data extraction is rarely a “set it and forget it” task. It requires solutions that understand SAP’s internal structures, respect the operational constraints of productive systems, and handle change and validation as first-class concerns. Recognizing these difficulties is the first step toward choosing an extraction approach that can reliably scale over time.
Common Approaches to SAP Data Extraction Tools
Most organizations do not begin with a clearly defined, long-term strategy for SAP data extraction. Instead, their approach evolves over time, shaped by immediate needs such as a new reporting requirement, a data warehouse initiative, or a regulatory obligation. As these needs accumulate, the chosen extraction methods reveal both their strengths and their limitations.
In practice, most SAP data extraction strategies fall into a small number of recognizable patterns.
SAP-native extraction options
Many teams start with extraction mechanisms that are part of the SAP ecosystem. This feels like a natural choice, especially for organizations with strong in-house SAP expertise. SAP-native options align closely with SAP’s authorization model, understand internal data structures, and fit neatly into existing SAP landscapes.
They are commonly used in scenarios such as:
- Feeding a limited set of SAP data into downstream reporting systems
- Sharing data between SAP applications
- Supporting standardized, well-defined extraction use cases
As long as the scope remains narrow, this approach can be effective. Challenges tend to emerge as data demands grow. Supporting additional consumers, increasing data volumes, or delivering SAP data to non-SAP environments often introduces significant operational complexity. Teams may find themselves relying on additional tooling or custom logic to fill gaps, which increases maintenance effort over time.
Custom-built extraction logic
Another widely used approach is to build extraction logic in-house. Teams create custom ABAP programs, define RFCs, or implement bespoke interfaces tailored to specific business requirements. This path is often chosen when flexibility is a priority or when existing tools do not appear to meet immediate needs.
Custom extraction is frequently used for:
- Highly specific reporting or compliance use cases
- One-off or time-bound data requirements
- Scenarios where precise control over logic is required
In the short term, this approach can deliver fast results. Over time, however, the drawbacks become more visible. Custom extraction logic is typically tightly coupled to individual SAP systems and processes. As requirements change, each adjustment requires development, testing, and coordination with SAP teams. Knowledge about how the extraction works may be concentrated with a few individuals, increasing operational risk and making long-term maintenance more difficult.
Generic ETL or ELT platforms
As their data architectures mature, organizations often look for ways to centralize data integration across many systems. Generic ETL or ELT platforms are frequently adopted to provide a unified way of moving data from multiple sources, including SAP.
This approach is attractive because it offers:
- A single integration platform for many data sources
- Familiar tooling for data engineering teams
- Consistent orchestration and scheduling
In practice, these platforms work reasonably well for smaller SAP datasets or less complex use cases. However, SAP often exposes their limitations. Because these tools are designed to be source-agnostic, SAP is typically treated as just another database or API. Teams may spend considerable time tuning performance, implementing custom delta logic, or compensating for SAP-specific behaviors. As data volumes and change frequency increase, maintaining reliable extraction can become increasingly labor-intensive.
Specialized SAP data extraction platforms
Some organizations ultimately adopt tools designed specifically for SAP data extraction. This usually happens after teams have experienced the operational friction of more general approaches.
Specialized platforms focus on automating the most challenging aspects of SAP extraction, including:
- Reliable handling of full and incremental loads
- Minimizing impact on productive SAP systems
- Built-in data validation and monitoring
- Consistent delivery of SAP data to multiple targets
Rather than treating SAP as a generic source, these platforms incorporate SAP-specific knowledge into the extraction process. This approach is often chosen when SAP data becomes a shared enterprise asset and reliability, scalability, and reduced maintenance effort become top priorities.
Choosing the right approach
In practice, each SAP data extraction approach reflects a different set of trade-offs. Some prioritize tight integration with SAP, and some emphasize flexibility or speed of implementation, while others focus on long-term operational reliability.
The table below summarizes how the most common SAP data extraction approaches compare across key relevant dimensions as SAP data usage grows in scale and complexity.
| Dimension | SAP-Native Extraction | Custom-Built Extraction | Generic ETL / ELT Platforms | Specialized SAP Extraction Platforms |
| Primary focus | SAP-internal data access | Solving specific custom needs | Broad, multi-source integration | Reliable SAP data extraction at scale |
| SAP awareness | Very high | High (depends on implementation) | Limited | Very high |
| Setup effort | Moderate to high | High | Moderate | Moderate |
| Ongoing maintenance | Moderate | High | Moderate to high | Low to moderate |
| Scalability | Limited outside SAP use cases | Limited by custom code | Varies by workload | Designed for scale |
| Change data capture | Available but often complex | Fully custom | Often requires tuning | Built-in and automated |
| Performance impact on SAP | Generally controlled | Depends on design quality | Can be challenging | Optimized for SAP workloads |
| Support for non-SAP targets | Limited | Custom per target | Strong | Strong |
| Data quality validation | Limited | Custom | Often externalized | Built-in |
| Operational visibility | Basic | Custom | Platform-dependent | Centralized and standardized |
| Typical use cases | Narrow, SAP-centric scenarios | Highly specific requirements | Mixed-source data platforms | Enterprise-wide SAP data delivery |
| Long-term sustainability | Moderate | Low to moderate | Moderate | High |
No single approach is universally better; the right choice depends on scale, complexity, and how central SAP data is to the organization. In many environments, teams move from left to right as SAP data becomes more widely consumed and reliability requirements increase.
Key Capabilities to Look for in SAP Data Extraction Tools
Once organizations recognize that SAP data extraction is an ongoing operational process — not a one-off integration task — the conversation naturally shifts from how to extract data to how well it can be done over time. This is where the choice of tooling becomes critical.
While specific implementations differ, effective SAP data extraction tools tend to share a common set of capabilities. These capabilities are less about individual features and more about how reliably the extraction process can operate under real-world conditions.
SAP-friendly performance management
Any tool extracting data from SAP must operate with a clear understanding of how sensitive productive SAP systems are. Extraction that works perfectly in a test environment can cause serious issues in production if performance is not carefully managed.
Strong SAP data extraction tools are designed to:
- Control and throttle extraction workloads
- Schedule jobs intelligently around business activity
- Minimize locking and contention
- Scale data volumes without overwhelming the source system
In practice, this means teams can extract the data they need without constantly negotiating extraction windows or worrying about the impact on end users.
Reliably handling changes over time
In most real-world scenarios, the biggest challenge is what happens after the initial extraction. SAP data is constantly changing, and downstream systems should reflect those changes accurately and consistently.
A robust extraction tool should support:
- Initial full loads and ongoing incremental updates
- Clear handling of inserts, updates, and deletions
- Recovery mechanisms when jobs fail or are interrupted
Without this, teams often fall back on frequent full reloads or manual reconciliation, both of which increase operational risk and cost as data volumes grow.
Built-in data validation and quality controls
One of the most underestimated aspects of SAP data extraction is validation. A job that is completed successfully from a technical perspective does not necessarily produce accurate or complete data.
Effective extraction tools help teams detect problems early by providing:
- Basic completeness checks (for example, record counts)
- Detection of partial or inconsistent loads
- Visibility into schema changes or unexpected data patterns
These controls turn extraction into a trustworthy process rather than a “black box” that teams only investigate after something goes wrong downstream.
Automation and operational visibility
Manual extraction processes do not scale, especially when SAP data feeds multiple systems and teams. Over time, the operational burden of monitoring, restarting, and troubleshooting jobs can exceed the effort of building the data pipelines themselves.
Modern SAP data extraction tools emphasize:
- Automated orchestration of extraction workflows
- Centralized monitoring and alerting
- Clear visibility into data freshness and pipeline health
This level of observability allows teams to manage SAP data extraction proactively, rather than reacting to issues after they affect business users.
Flexibility in data delivery
SAP data rarely has a single destination. The same datasets may be simultaneously consumed by analytics platforms, operational applications, and integration layers.
As a result, extraction tools should be able to:
- Deliver data to multiple targets without duplicating logic
- Support both cloud and on-premise environments
- Adapt as data architectures evolve
Flexibility at the delivery layer reduces the need to rebuild extraction pipelines whenever a new use case or platform is introduced.
Designed for long-term sustainability
Perhaps the most important capability is not visible in any single feature: sustainability over time. SAP landscapes evolve, business requirements change, and data volumes grow. Tools that work only under ideal conditions quickly become a source of friction.
Sustainable SAP data extraction tools are characterized by:
- Reduced reliance on custom code
- Predictable operational behavior
- The ability to absorb change without constant redesign
This is what allows SAP data extraction to fade into the background — not because it is unimportant, but because it works reliably enough that teams no longer have to think about it every day.
How DataLark Approaches SAP Data Extraction
When organizations mature beyond ad-hoc extraction scripts and home-grown pipelines, the focus naturally shifts toward treating SAP data extraction as operational infrastructure. DataLark’s approach reflects this mindset by combining deep SAP-specific integration with automation, validation, and delivery flexibility to support real-world enterprise needs.
DataLark is built to help teams reliably extract, prepare, and deliver SAP data to any downstream destination for reporting, integration, or broader consumption. Its design emphasizes security, repeatability, and visibility throughout the extraction lifecycle.
A more SAP-aware extraction foundation
At the heart of DataLark’s approach is its deep alignment with SAP systems:
- It connects natively to SAP ECC and SAP S/4HANA environments, supporting core modules such as Materials Management (MM), Sales & Distribution (SD), Financials (FI/CO), and more.
- It uses standard integration protocols like RFC, BAPI, and OData to ensure reliable communication with SAP while preserving complex relationships and metadata.
- The platform supports extraction from custom SAP tables as well as standard ones, allowing teams to bring any needed business data into their integration workflows.
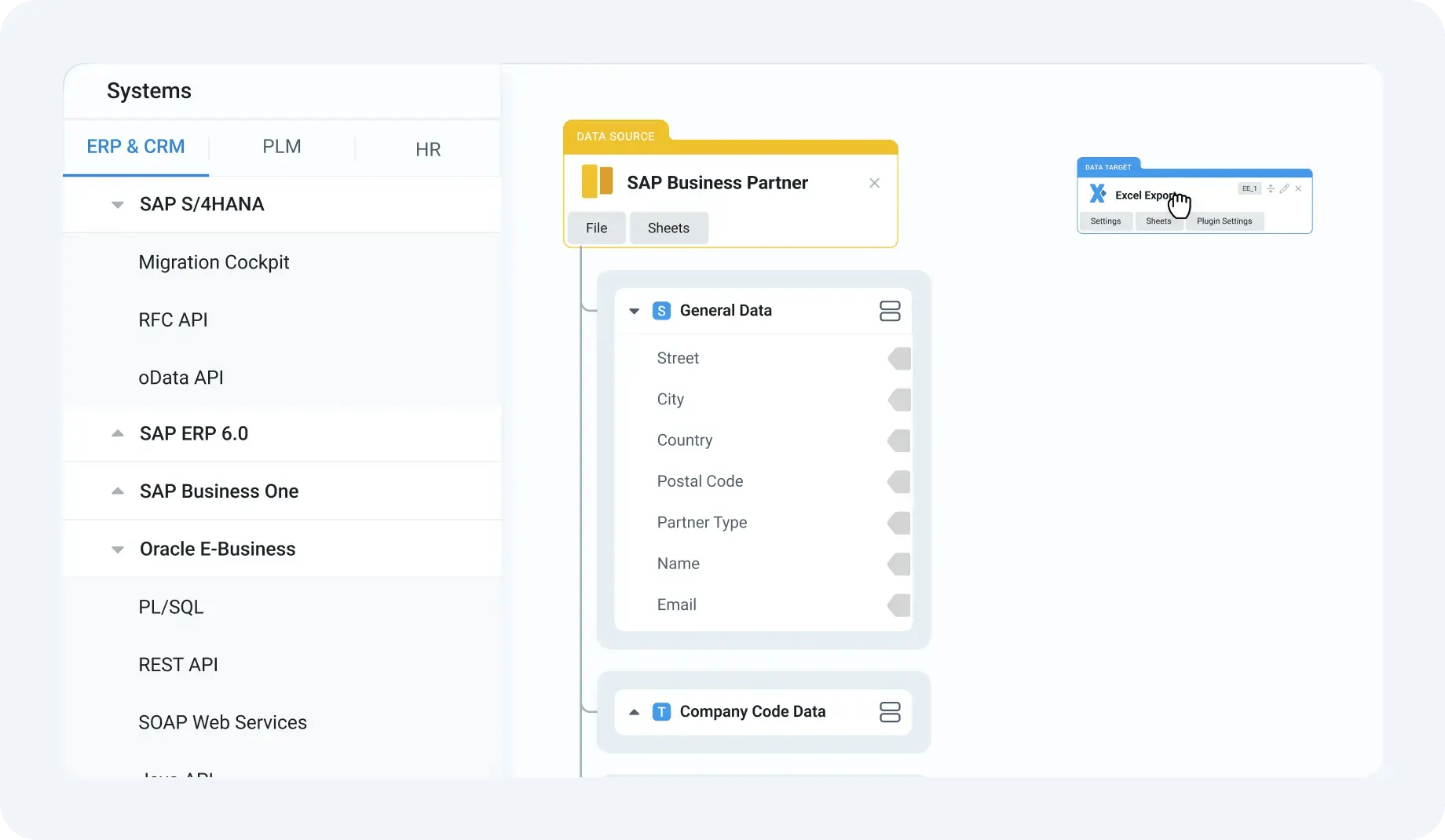
This SAP-centric foundation helps avoid common pitfalls where generic tools misunderstand SAP structures or push responsibility back onto users.
No-code configuration and flexible mapping
DataLark takes a no-code / low-code approach to designing extraction workflows, lowering technical barriers and reducing dependency on specialized SAP developers:
- Users define extraction logic through an intuitive graphical interface, visually mapping SAP data points to targets such as warehouses, lakes, BI tools, or flat files.
- The platform detects potential mapping issues early and guides users with feedback, reducing trial-and-error configuration.
- Transformations (e.g., standardizing formats, renaming fields, or removing duplicates) can be incorporated into extraction flows without writing code.
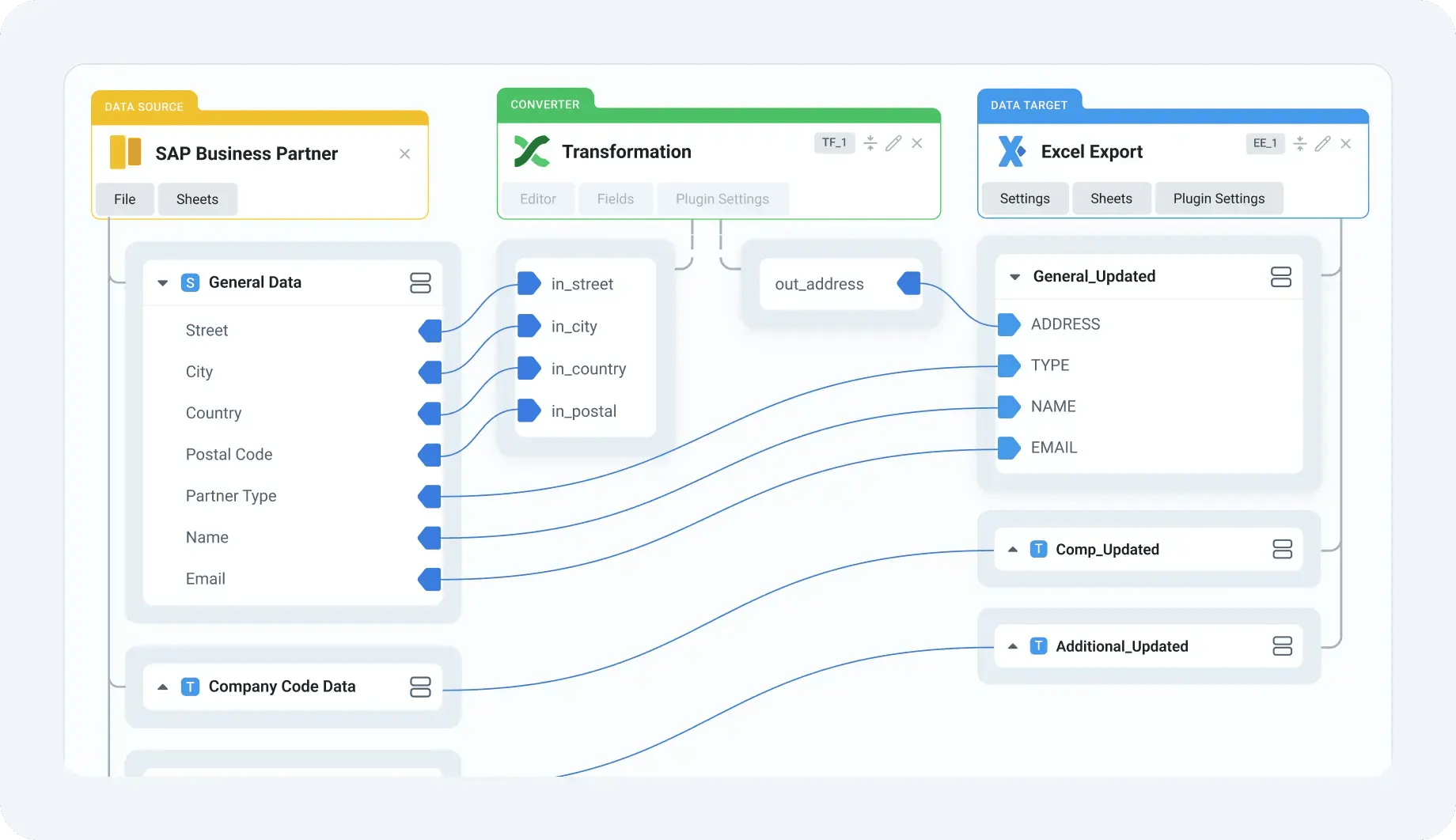
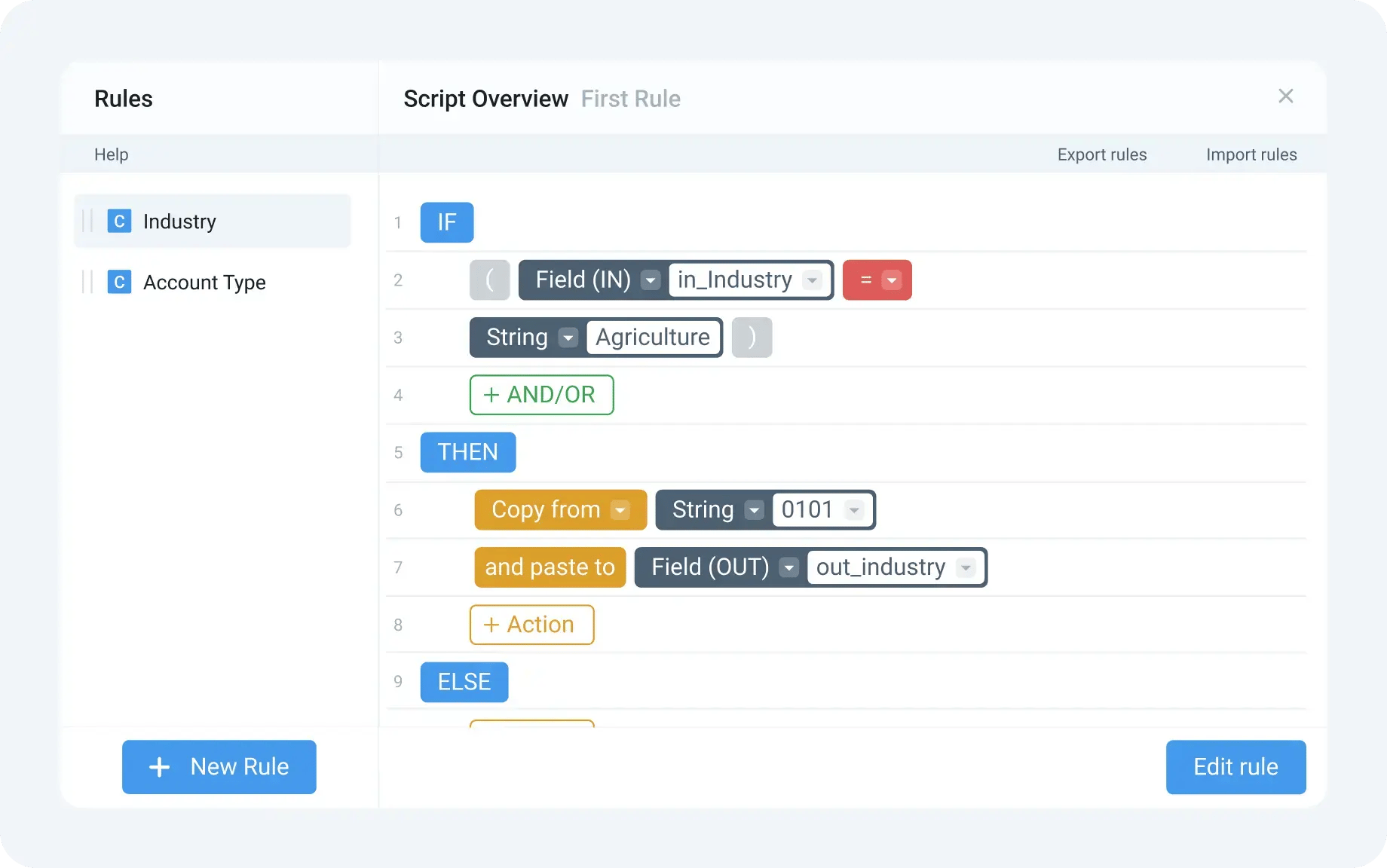
This setup streamlines extraction logic creation and makes it more accessible to both technical and operational teams.
Automated scheduling, deltas, and delivery
One of the hardest parts of SAP extraction isn’t getting data one time; it’s running it consistently over time in a way that scales without burdening source systems:
- DataLark supports scheduled extraction as well as event-driven or incremental (delta) loads, helping teams minimize impact on productive SAP workloads.
- Incremental loads can be configured using standard SAP mechanisms (e.g., timestamps, change pointers) or custom logic where needed, optimizing refresh windows and resource use.
- Extracted data can be delivered to a broad range of destinations (e.g., cloud data warehouses like Snowflake and BigQuery, SQL databases, BI tools, or simple Excel exports) enabling broad downstream use without additional pipeline work.
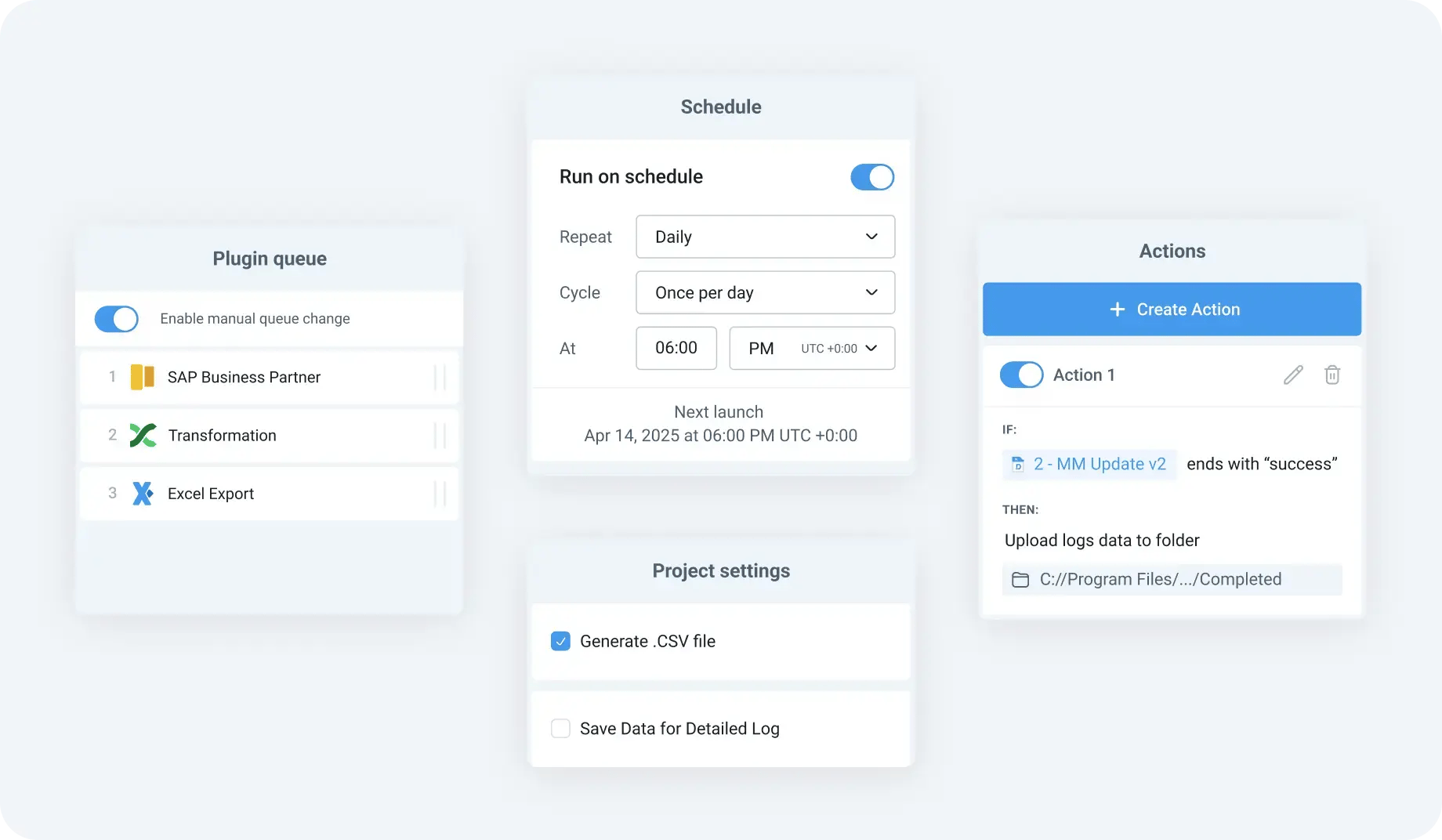
This flexibility makes it easier for enterprises to centralize SAP data flows without repeatedly reinventing extraction logic for every new consumer.
Validation, monitoring, and operational traceability
Reliable extraction is about more than data movement; it is about creating trust in how SAP data is delivered and used:
- DataLark includes validation capabilities that help ensure data meets business expectations before it moves downstream.
- Execution logs, status reporting, and notification options give teams clear visibility into what has been extracted, whether loads succeeded, and where attention might be needed.
- Auditable extraction execution history and traceability support internal oversight and compliance requirements.
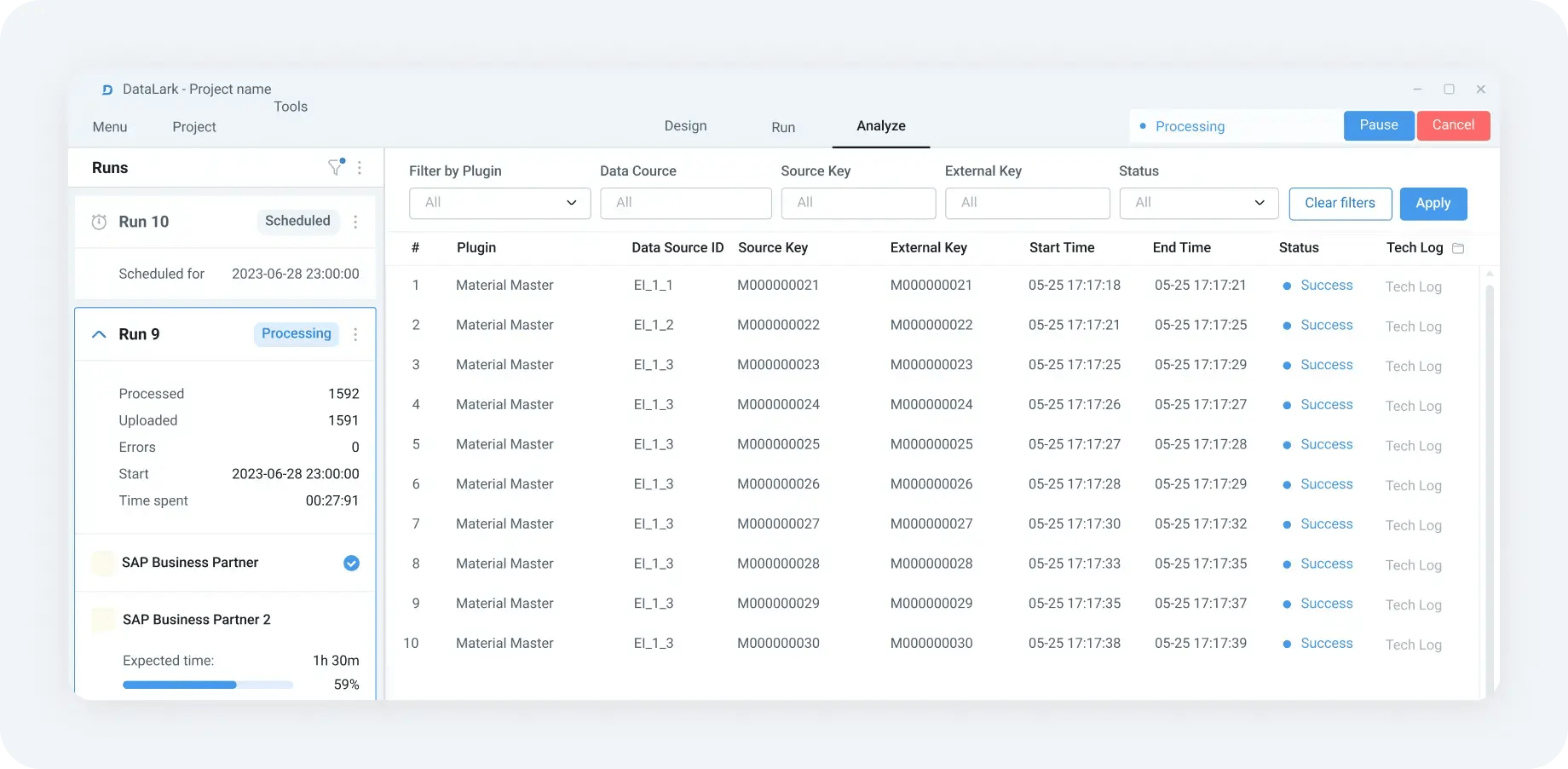
This operational visibility shifts extraction from a black box to a managed process, thus reducing surprises and enabling proactive error handling.
Aligning SAP extraction with broader data needs
Importantly, DataLark does not try to provide analytics or reporting within its extraction capabilities. Instead, it positions extraction as a foundational data movement and preparation layer:
- The output of SAP extraction is ready for any next step — whether feeding a central data warehouse, supporting operational integration, or underpinning machine learning workloads.
- By separating extraction from interpretation, organizations gain flexibility. They can evolve analytics tools or use new platforms without reengineering extraction pipelines.
Seen this way, DataLark’s approach turns SAP data extraction into repeatable infrastructure rather than ad-hoc engineering.
When DataLark Is the Right Choice (and When It’s Not)
No SAP data extraction solution is universally appropriate. The right choice depends on how central SAP data is to the organization, how many systems depend on it, and how much operational reliability is required. Being clear about these factors helps teams avoid both under-engineering and unnecessary complexity.
DataLark is a strong fit in environments where SAP data extraction has moved beyond isolated tasks and become an ongoing operational responsibility.
It is particularly well suited when:
- SAP is a core enterprise system, and its data is consumed by multiple downstream platforms or teams.
- Extraction needs to run continuously, not as occasional or manual exports.
- Data quality and consistency matter, because SAP data supports reporting, automation, or regulatory processes.
- Custom extraction logic has become difficult to maintain, and teams want to reduce reliance on bespoke SAP development.
- Operational visibility is required, so teams can understand what data was extracted, when, and with what outcome.
In these scenarios, DataLark helps standardize how SAP data is extracted and delivered, reducing operational effort while increasing confidence in the data being shared.
At the same time, DataLark is not designed for every SAP data use case. It may not be the best choice when:
- Data needs are limited to one-off or infrequent exports.
- SAP data is used only for ad-hoc analysis, without ongoing refresh requirements.
- Data volumes are very small, and operational overhead is minimal.
- There is no need for automation, monitoring, or long-term scalability.
In such cases, simpler extraction methods may be sufficient and more cost-effective.
The distinction is less about tool capability and more about operational intent. When SAP data extraction is treated as temporary or incidental, lightweight solutions often suffice. When it becomes a foundational part of the data landscape, a purpose-built extraction layer becomes increasingly valuable.
SAP Data Extraction as the Foundation for Analytics, AI, and Automation
As SAP environments evolve, the role of SAP data is expanding beyond traditional reporting and analytics. New capabilities — particularly those driven by AI and intelligent automation — increasingly depend on having SAP data available in a form that is not only accurate, but also well-structured, contextualized, and accessible outside transactional systems.
This shift becomes especially visible with the introduction of AI-driven assistants such as SAP Joule. Joule is designed to support users by answering questions, surfacing insights, and assisting with decision-making across SAP processes. To do this effectively, it relies on more than isolated data points. It requires consistent access to business-relevant SAP data, properly aligned across systems and time.
In this context, SAP data extraction plays a strategic role. It determines whether SAP data can be prepared, enriched, and reused across multiple intelligent use cases. Extraction that is designed with reuse in mind makes it possible to support analytics, automation, and AI initiatives in parallel, without fragmenting the data landscape.
AI and automation also place new demands on SAP data. Historical continuity, semantic consistency, and traceability become increasingly important when data is used to train models, drive recommendations, or trigger automated actions. These requirements go beyond basic data availability and highlight the need for SAP data to be extracted as a dependable, well-managed asset.
In essence, SAP data extraction is a key enabler of how SAP data can participate in the next generation of intelligent enterprise scenarios, including those shaped by SAP Joule and similar AI-driven technologies.
Conclusion
SAP data extraction is often approached as a technical necessity — something to solve quickly so downstream initiatives can move forward. In reality, it is a long-term architectural decision that shapes how reliably SAP data can be used across the organization.
As SAP landscapes grow more complex and SAP data supports an increasing number of use cases, extraction can no longer be treated as an isolated task or a collection of one-off pipelines. The most sustainable approaches are those that minimize operational risk, reduce dependence on custom logic, and make SAP data consistently available to many consumers over time.
Choosing the right SAP data extraction approach is therefore less about individual features and more about operational intent. Solutions that work for narrow or temporary needs often struggle as data volumes grow, requirements change, and new initiatives (e.g., advanced analytics, automation, or AI) come into play. Treating extraction as foundational infrastructure helps organizations avoid repeated rework and enables SAP data to evolve alongside the business.
DataLark is built with this long-term perspective in mind. Focusing on automated, SAP-aware data extraction with built-in validation and delivery flexibility helps organizations turn SAP data extraction into a stable, repeatable process. Instead of embedding extraction logic into every downstream system, DataLark centralizes it where SAP complexity can be managed once and reused broadly.
For organizations looking to make SAP data more accessible, trustworthy, and ready for future use cases, it is essential to strengthen the extraction foundation itself.
To learn how DataLark can support a sustainable approach to SAP data extraction, request a demo or get in touch to discuss your SAP data landscape.