Struggling with SAP Data Migration Cockpit load failures? Learn how to prepare data before cutover for predictable S/4HANA migration runs.
SAP Data Migration Cockpit: Why Loads Fail Repeatedly and How to Fix It Before Cutover
If you run SAP Data Migration Cockpit loads and see the same errors again and again, you’re not alone, and you’re probably not doing anything “wrong.”
You fix mandatory fields; reload.
You adjust mappings; reload.
You correct duplicates; reload again.
And somehow, the next test cycle still fails, often for reasons that feel frustratingly familiar.
As cutover approaches, pressure builds. Migration cycles stretch. Confidence drops. And what started as a structured SAP migration begins to feel like controlled chaos held together by spreadsheets, scripts, and late-night troubleshooting sessions.
Here’s the uncomfortable truth most S/4HANA migration teams discover too late: SAP Data Migration Cockpit is rarely the reason loads fail repeatedly. The real issue is the state of the data before you ever press “Load.”
This article explains:
- Why Migration Cockpit failures tend to appear late.
- What SAP Data Migration Cockpit is — and is not — designed to handle.
- Why “fix-and-reload” cycles keep happening.
- How successful teams prevent these failures before cutover.
- And how DataLark fits into this picture as a data preparation and validation layer that works with, not instead of, Migration Cockpit.
If you’re already deep into an S/4HANA migration and struggling to stabilize your loads, this is written for you.
What SAP Data Migration Cockpit Is — and What It Is Not
SAP Data Migration Cockpit is the standard SAP tool for loading data into S/4HANA. It provides predefined migration objects, staging tables or XML templates, and a controlled execution framework supported by SAP.
It does several things very well:
- Enforces target structure consistency
- Applies SAP-side validations
- Provides a standardized way to load data into S/4HANA
- Serves as a single execution point for migration objects
This is why SAP Migration Cockpit is widely adopted and recommended. It gives structure and governance to the load itself. However, many projects struggle to understand the boundaries of Migration Cockpit.
SAP Data Migration Cockpit is not designed to:
- Cleanse or harmonize data from multiple source systems.
- Reconcile inconsistencies across ECC, non-SAP systems, and spreadsheets.
- Perform complex, repeatable transformations across iterations.
- Detect systemic data quality issues early in the migration lifecycle.
Migration Cockpit assumes that the data you hand to it is already reasonably well-prepared. And that assumption is where many migration projects quietly break down.
Why SAP Data Migration Cockpit Loads Fail Repeatedly
On most S/4HANA migration projects, SAP Data Migration Cockpit failures don’t appear as a single dramatic breakdown. Instead, they emerge gradually over multiple test cycles, creating a pattern that is both familiar and deeply frustrating for migration teams.
The first load attempt often goes reasonably well. A large portion of the data is accepted, and the initial errors seem manageable and expected. Typically, teams encounter issues such as:
- Missing mandatory fields in a subset of records
- Invalid or incomplete values that do not meet S/4HANA requirements
- Obvious duplicates that were overlooked during initial preparation
These problems are addressed, corrections are applied, and the team prepares for the next load with the expectation that the worst is behind them.
Instead, the second or third execution often tells a different story. Rather than stabilizing, the load produces new errors. Some resemble previous issues, while others are completely different. Records that passed earlier suddenly fail, and it is not always clear what has changed. At this stage, Migration Cockpit begins to feel unreliable, even though the migration object configuration itself remains unchanged.
As testing continues, a familiar cycle takes hold. Each load reveals another layer of data problems, pushing the team into repeated fix-and-reload iterations. These iterations are costly because they require coordination across multiple roles and systems:
- Functional experts validating business rules
- Technical teams adjusting extracts, mappings, or transformations
- Project leads managing growing pressure as timelines compress
What makes this especially challenging is that the data often appears correct when reviewed outside of SAP. Spreadsheets look clean, mappings are logically defined, and no single issue explains why failures keep occurring. The problem is not obvious because it is not isolated.
In reality, SAP Data Migration Cockpit is doing exactly what it is designed to do. It applies SAP’s validation rules at execution time, and many data issues only surface after earlier errors have been resolved or when related objects are processed together. As a result, problems are exposed incrementally rather than all at once, creating the impression of repeated failure even though the underlying data issues existed from the beginning.
Because these issues are discovered during load execution, teams are forced into a reactive mode of working. Investigation happens under time constraints, fixes are applied quickly to keep the project moving, and confidence in the migration process gradually erodes as cutover approaches.
What looks like instability in SAP Data Migration Cockpit is, in fact, a visibility problem. The tool is surfacing unresolved data quality and consistency issues late in the migration lifecycle, when there is little room left to address them calmly or systematically.
The Real Root Cause: Data Isn’t Ready When You Press “Load”
Once teams step back from individual Migration Cockpit errors, a broader pattern usually becomes clear. The problem is not a specific field, mapping, or object configuration. The problem is that the data reaching SAP Data Migration Cockpit is simply not ready for execution.
In most S/4HANA migration projects, data does not come from a single, clean system. Instead, it is assembled from multiple sources that were never designed to work together. Core data may come from ECC, while additional attributes are pulled from non-SAP systems, legacy databases, or spreadsheets maintained outside of IT. Each source follows its own rules, formats, and assumptions.
To bridge these gaps, teams rely heavily on manual preparation. Data is extracted, adjusted, and reconciled using a combination of Excel files, SQL queries, and custom scripts. At first, this feels efficient because it allows quick fixes and visible progress. Over time, however, this approach creates structural weaknesses that are difficult to control.
Common symptoms of this stage include:
- The same data being adjusted differently by different teams
- Transformations that exist only in individual spreadsheets or scripts
- Validation rules that are applied inconsistently or not documented
- Uncertainty about whether today’s data is better or worse than yesterday’s
Because these preparation steps are fragmented, there is no single, reliable view of data readiness. Teams may know that some checks were performed, but not exactly which ones, when, or with what results. As long as data “looks reasonable,” it is passed forward to Migration Cockpit.
The issue is that Migration Cockpit is the first place where all data is evaluated together under SAP’s rules. Only at load time does SAP enforce mandatory fields, value constraints, and structural consistency across records and objects. When data preparation is incomplete or inconsistent, Migration Cockpit becomes the point of discovery rather than execution.
This late discovery is what drives repeated failures. Problems that were hidden across multiple files and systems suddenly become visible, but only one layer at a time. Teams fix what they can see, reload, and then uncover the next issue. The data improves incrementally, but the process feels unstable because readiness is never assessed as a whole.
As a result, migration teams end up working without clear answers to critical questions:
- Which data quality issues have already been resolved?
- Which ones are still present but not yet exposed?
- What changed between the last successful load and the current failure?
Without clear, repeatable preparation and validation before execution, pressing “Load” in Migration Cockpit becomes a test rather than a controlled step. Each run is an experiment, and every failure feels like a setback rather than an expected outcome of a managed process.
This is the real root cause behind repeated Migration Cockpit failures. The data is not failing because SAP’s rules are too strict; it is failing because those rules are being applied too late, after the project has already committed to execution.
The Missing Layer in Most Migration Cockpit Projects
Once teams recognize that repeated Migration Cockpit failures are not random, the natural question becomes, “What’s missing?” The answer is usually not another script, another spreadsheet, or another round of load retries. What’s missing is a dedicated layer that sits between raw source data and SAP Data Migration Cockpit.
In many migration projects, data preparation grows organically. Early extracts are adjusted manually, small fixes are made where problems appear, and over time a collection of files, scripts, and local rules emerges. Each individual step may make sense in isolation, but together they form a fragile process that is difficult to repeat or control.
What’s absent in this setup is a clear separation between data engineering and data execution. Migration Cockpit is expected to load data, but it also becomes the place where data issues are discovered, analyzed, and sometimes even worked around. This overload of responsibility is what turns a structured SAP tool into a perceived bottleneck.
Projects that stabilize Migration Cockpit loads usually do one thing differently: they introduce a formal data preparation layer before execution. This layer is not about replacing SAP data migration tools; it is about giving them better inputs. Its role is to absorb the complexity of source data so that Migration Cockpit can focus on what it does best.
A proper preparation layer takes ownership of tasks that are otherwise scattered across teams and tools, including:
- Collecting data from all source systems into a single controlled dataset
- Standardizing formats, keys, and structures consistently across iterations
- Applying transformation and mapping rules in a repeatable way
- Validating data before execution, not during it
When this layer exists, data issues are identified earlier and in context. Instead of reacting to load errors, teams work with clear validation results and actionable fix lists. Migration Cockpit stops being the first place where problems appear and becomes the final execution step in a controlled process.
Just as importantly, this layer creates continuity across environments and test cycles. The same rules are applied in development, quality assurance, and production. Changes are visible, traceable, and deliberate, rather than accidental. Teams can finally answer questions such as what changed between runs, why a load behaved differently, and whether data quality is improving over time.
Without this missing layer, migration projects rely heavily on individual expertise and manual effort. Success depends on who is available, which spreadsheet version is used, and how much time there is before the next load. With it, migration becomes a managed process rather than a series of firefighting exercises.
This is the gap that most Migration Cockpit projects struggle with; it is the gap that solutions like DataLark are designed to fill.
How DataLark Works with SAP Data Migration Cockpit
Once a dedicated data preparation layer is introduced, the role of SAP Data Migration Cockpit becomes much clearer. Instead of being the place where data problems are discovered and debugged, it becomes what it was designed to be: the controlled execution point for loading data into S/4HANA. DataLark operates upstream of this execution step, taking ownership of the work that typically overwhelms migration teams long before a load ever starts.
In practice, this means DataLark sits between source systems and Migration Cockpit, absorbing the complexity of data extraction, transformation, and validation so that the Cockpit receives data that is already migration-ready. The two tools are not competing; they are addressing different parts of the same process.
There are several steps involved with preparing data for Migration Cockpit.
Step 1: Collecting data from real-world source landscapes
On real projects, data rarely comes neatly packaged from a single ECC system. A typical migration might involve core master data from ECC, supplemental attributes from a legacy CRM, pricing or classification data from a custom database, and corrections maintained manually in Excel. Without a central preparation layer, these inputs are handled separately, often by different people, and reconciled only at the last moment.
DataLark addresses this by ingesting data from all relevant sources into a single, governed staging area. SAP data can be pulled using standard interfaces, while non-SAP databases and flat files are brought in through controlled connectors. The key difference is not just technical access, but ownership: once data is in DataLark, it becomes part of a single, managed dataset rather than a collection of loosely related extracts.
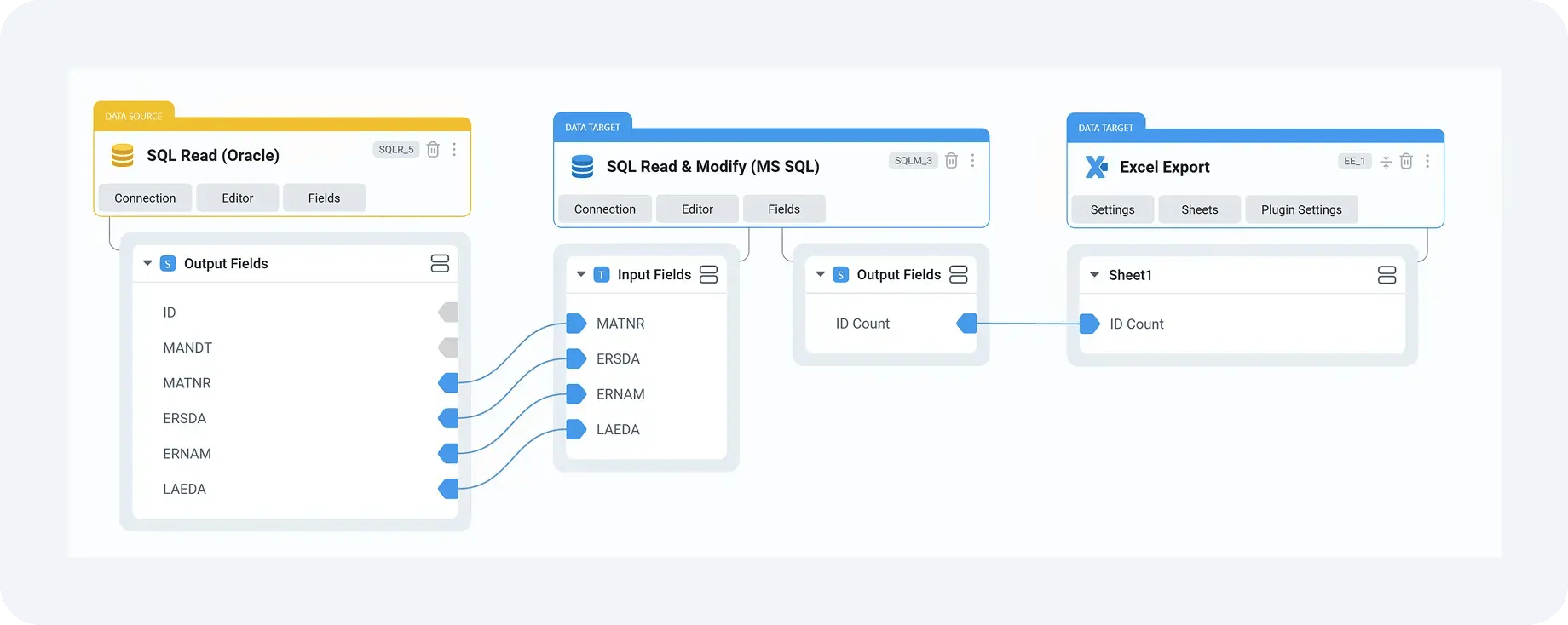
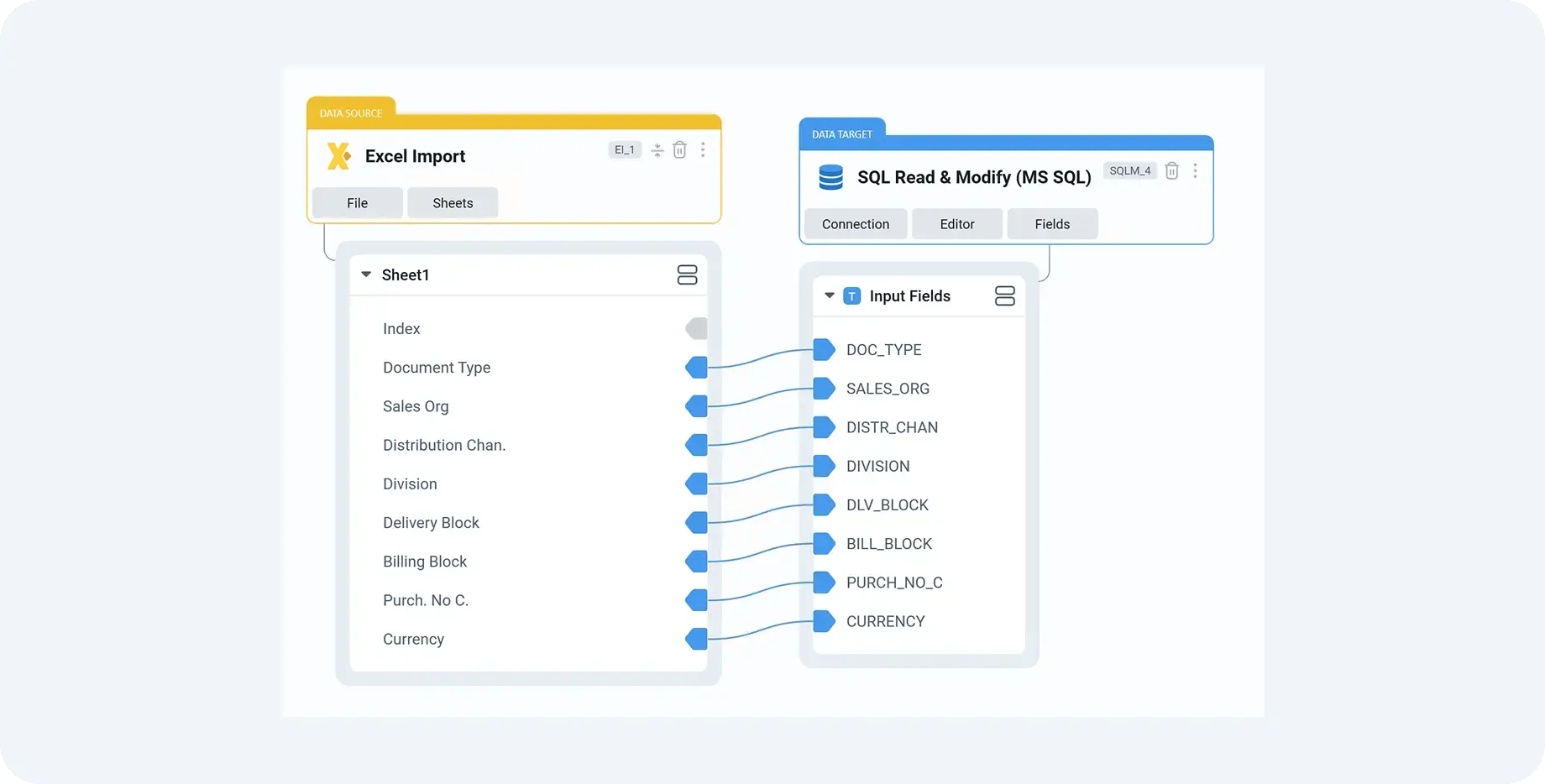
For example, on a customer master migration, business partner data may originate in ECC, while address enrichments or classification attributes are maintained externally. DataLark allows these datasets to be combined early, making inconsistencies visible before they reach SAP. Instead of discovering missing address fields during a Migration Cockpit load, teams can see and correct them during preparation, when the impact is far lower.
Step 2: Normalizing and mapping with repeatability in mind
Mapping legacy data to S/4HANA structures is rarely a one-time effort. Rules evolve as understanding improves, and what works for one test cycle often needs adjustment for the next. In many projects, these changes are implemented directly in spreadsheets or ad-hoc scripts, making it difficult to understand which rules were applied in which run.
DataLark approaches this differently by treating mapping and transformation logic as reusable, versioned rules. Formats (e.g., dates, units of measure, and codes) are standardized consistently across runs. Joins between related datasets are defined explicitly rather than recreated manually each time. When a rule changes, its impact can be understood and tested deliberately.
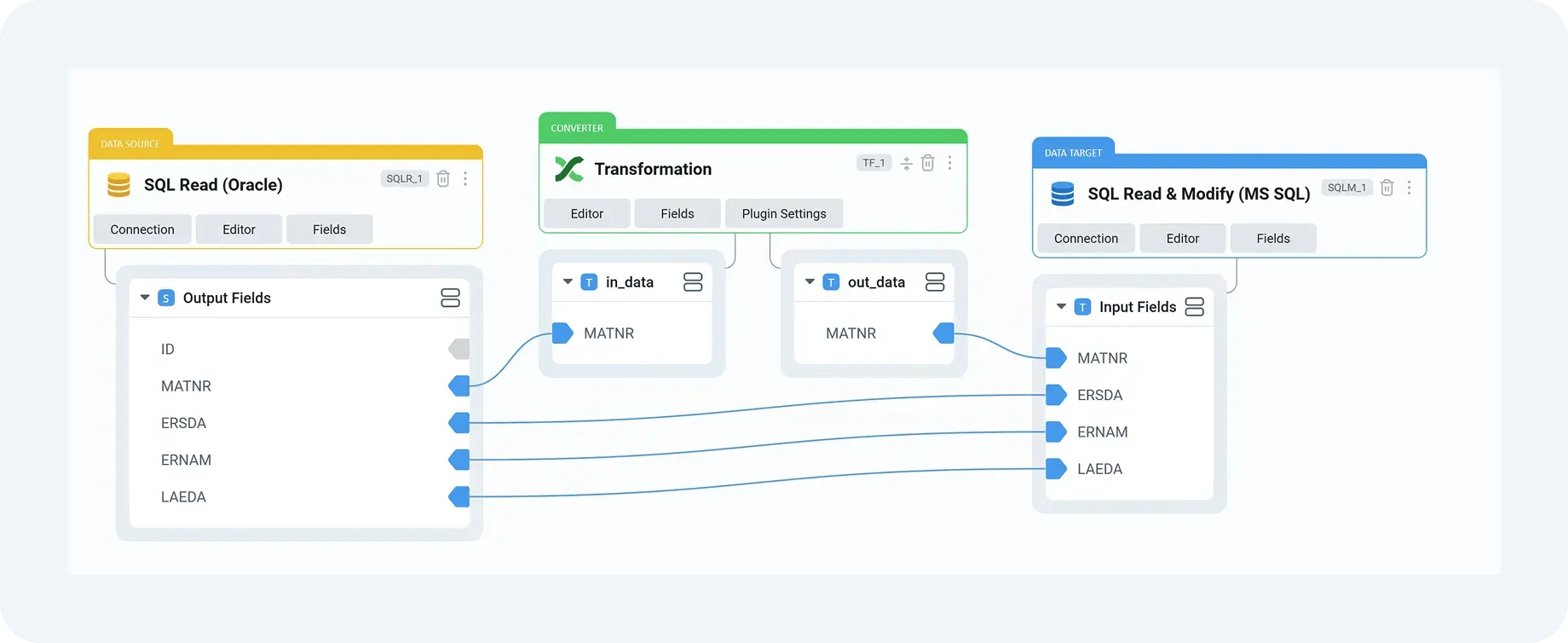
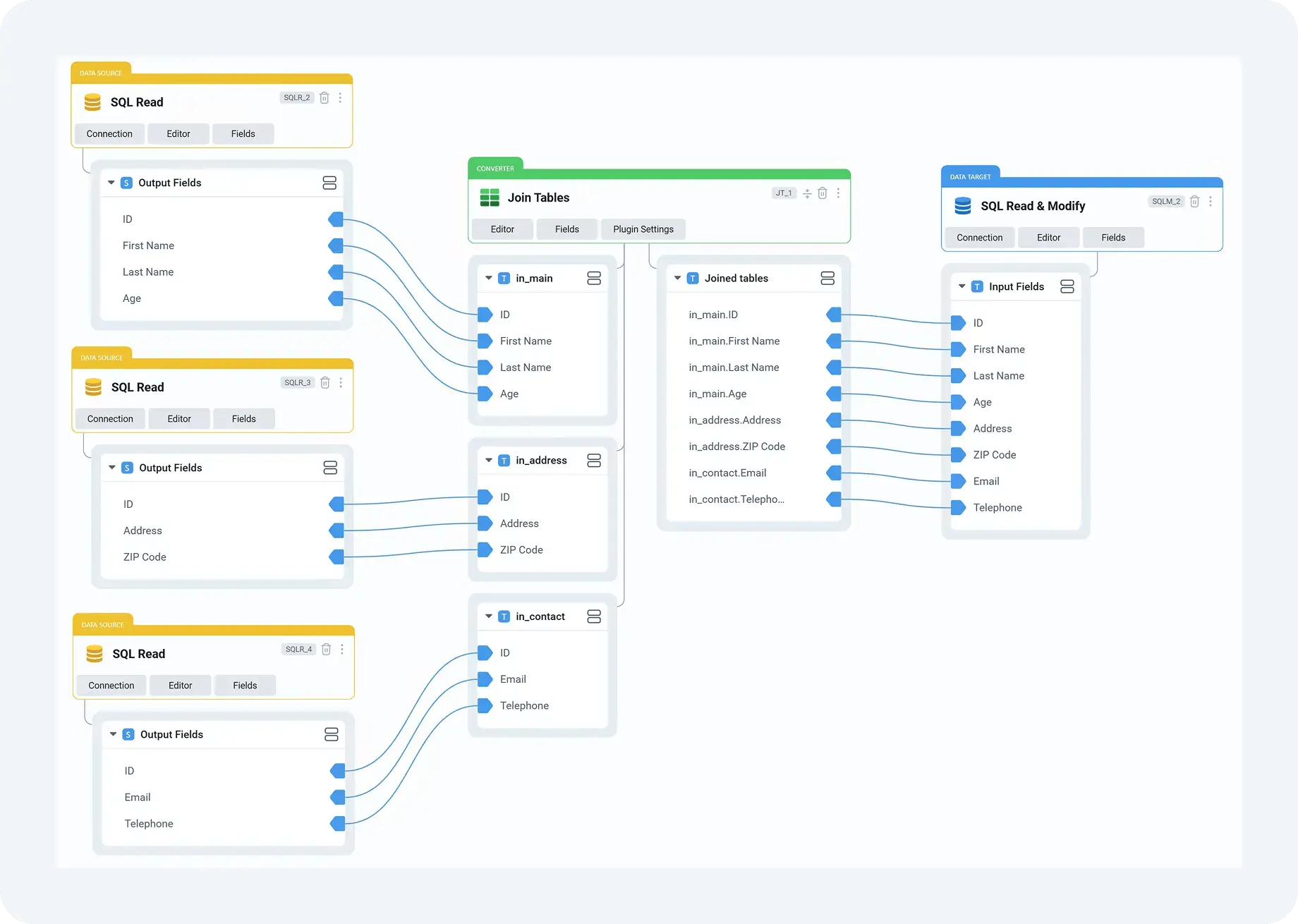
Consider a material master migration where legacy unit conversions or classification mappings need refinement after initial testing. With DataLark, these changes are applied once and reused across all subsequent cycles. Migration Cockpit then receives data that is structurally consistent, regardless of how many times the load is repeated or which environment it runs in.
Step 3: Validating data before it reaches SAP
One of the most significant differences DataLark introduces is timing. Instead of relying on Migration Cockpit to surface errors during execution, DataLark performs pre-load validations before data is handed over to SAP.
These validations typically include:
- Checks for mandatory fields based on target object requirements
- Detection of duplicates across large datasets
- Format and value consistency checks
- Basic referential integrity between related objects
The value here is not just catching errors earlier, but catching them in context. Instead of a generic load failure message, teams receive clear validation results that point directly to problematic records and the rules they violate. This allows data issues to be fixed systematically, rather than one load error at a time.
On projects with tight timelines, this shift alone can significantly reduce the number of Migration Cockpit load attempts. Teams stop using SAP loads as a diagnostic tool and start using them as a confirmation step.
Step 4: Delivering clean, auditable inputs to Migration Cockpit
Once data passes preparation and validation, DataLark delivers it to SAP Data Migration Cockpit in the format expected by the project. Depending on the setup, this may involve populating Migration Cockpit staging tables directly or generating structured XML templates ready for upload.
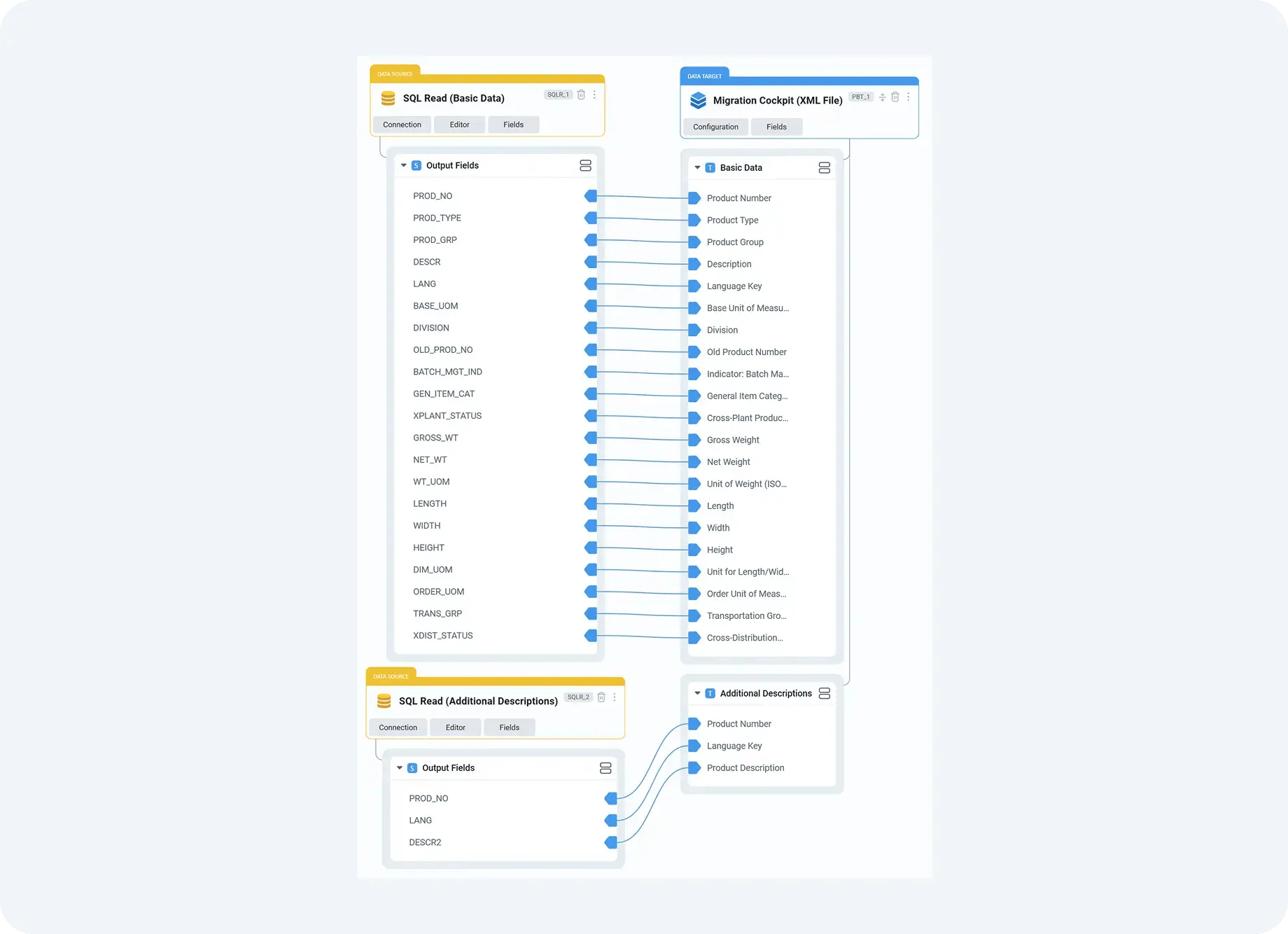
From the perspective of Migration Cockpit, nothing unusual is happening. It receives data in the correct structure and executes the load using standard SAP mechanisms. The difference is that the data arriving at this point has already been through a controlled, repeatable preparation process.
This separation has practical benefits during testing and cutover. When a load behaves unexpectedly, teams can trace exactly which data was delivered, which rules were applied, and what changed since the previous run. Troubleshooting shifts from guesswork to analysis.
What this looks like on stable projects
On projects where DataLark is used alongside SAP Data Migration Cockpit, migration cycles tend to follow a different rhythm. Instead of repeated reactive fixes, teams work through clear preparation and validation steps, with Migration Cockpit serving as the final gate rather than the first point of failure.
Over time, this leads to fewer load attempts per object, faster resolution of issues, and greater confidence as cutover approaches. More importantly, it changes how teams experience Migration Cockpit itself. What once felt unpredictable becomes consistent, because the variability has been addressed earlier in the process.
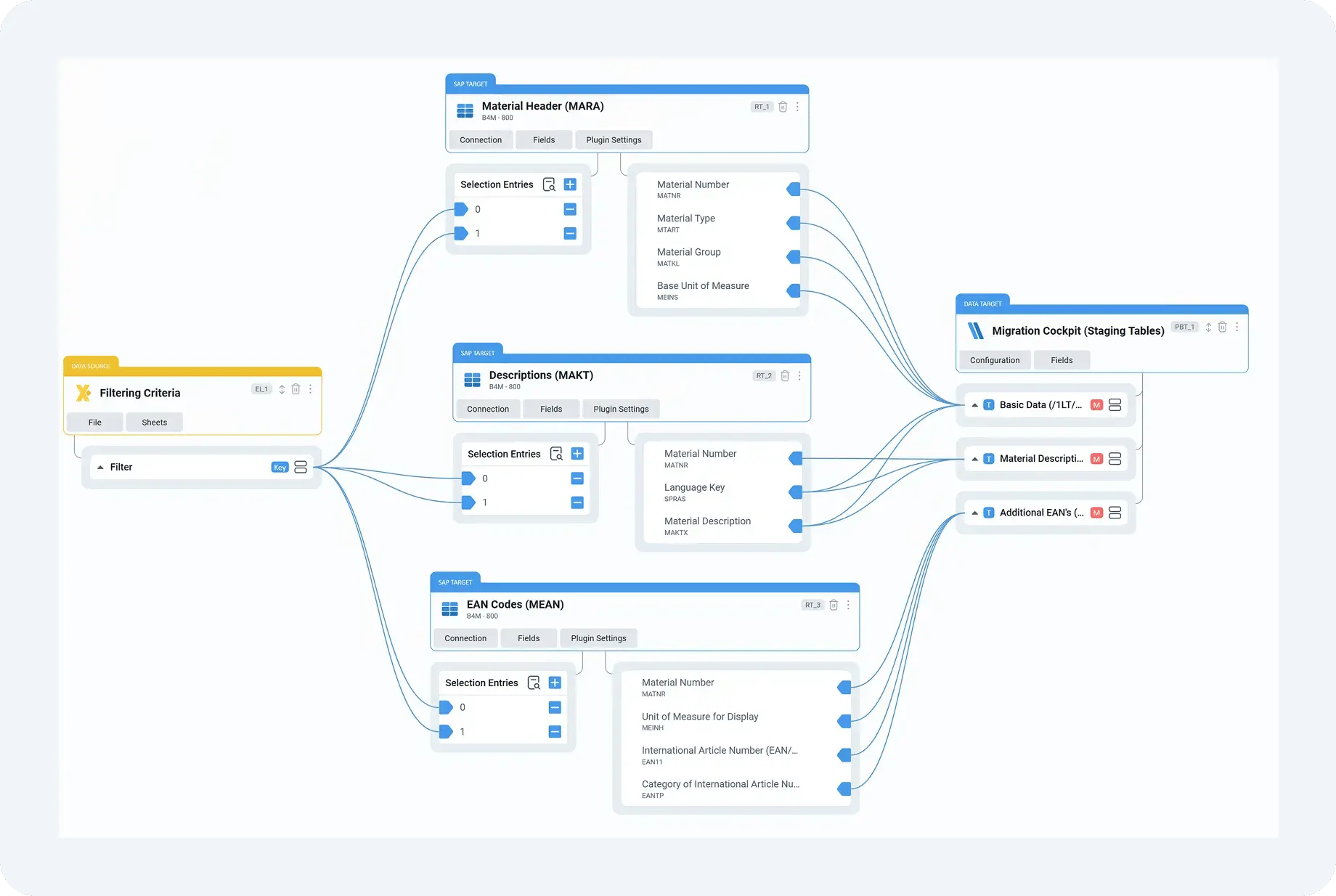
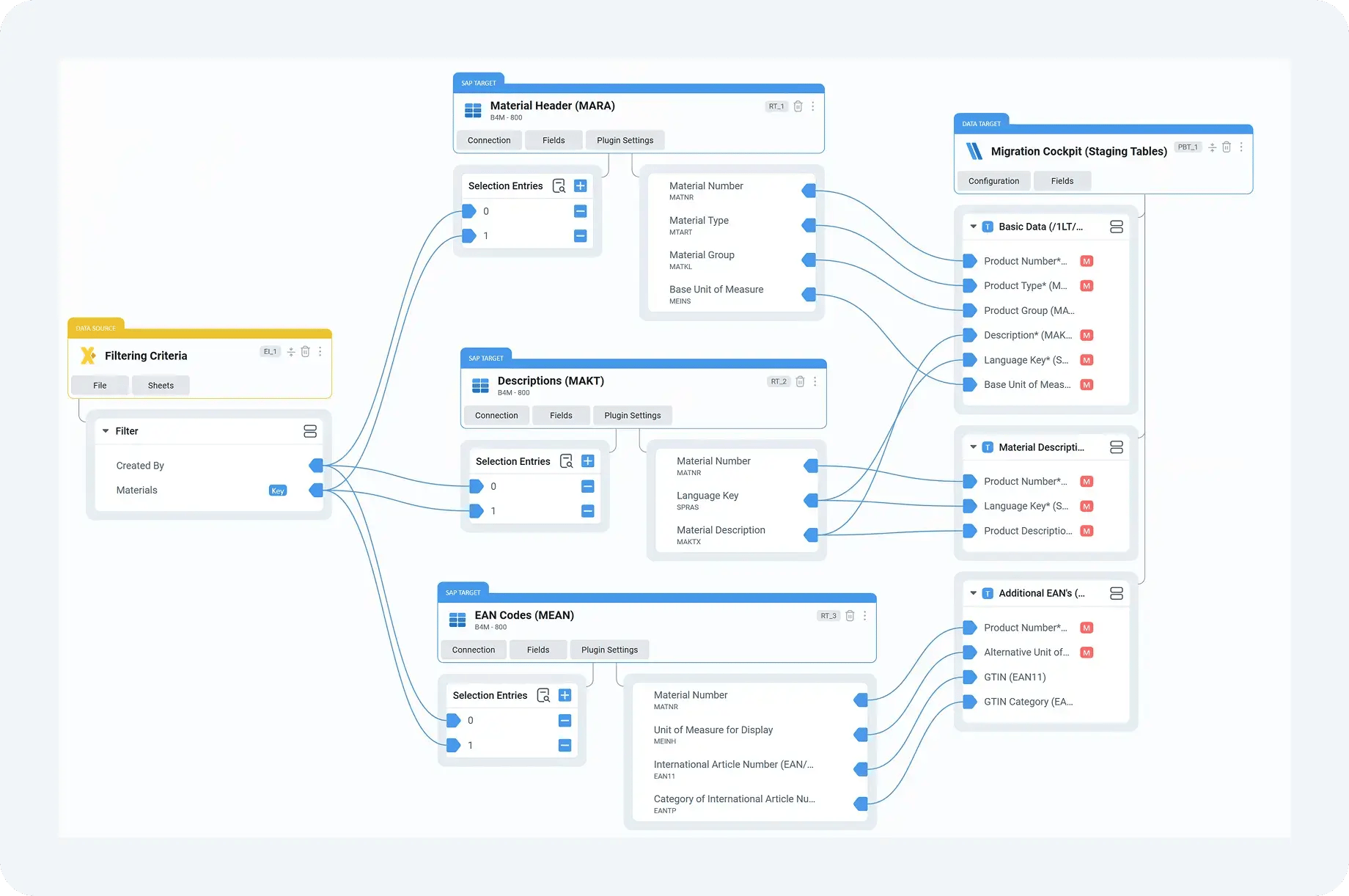
In this setup, SAP Data Migration Cockpit remains the execution standard, exactly as SAP intends. DataLark simply ensures that when data reaches that execution step, it is ready to succeed.
What Changes When Data Is Fixed Before Cutover
As an S/4HANA migration moves closer to cutover, the impact of unresolved data issues becomes increasingly visible. What might feel like manageable friction during early test cycles can quickly turn into a serious delivery risk. Fixing data issues before execution changes the entire dynamic of how migration teams work in the final phase.
When data is prepared and validated upstream of SAP Data Migration Cockpit, teams typically see several concrete changes:
- Migration Cockpit loads become predictable rather than experimental: Instead of treating each load as a test to see what fails next, teams approach execution with a clear expectation of the outcome. Data has already been standardized and validated, so Migration Cockpit is no longer the first place where problems surface. This predictability allows teams to plan migration cycles with confidence and reduces last-minute surprises.
- Fix-and-reload cycles are significantly reduced: Repeated load attempts are one of the biggest sources of stress near cutover. When data issues are addressed only during execution, each fix risks uncovering new errors. By resolving the majority of data quality and consistency problems before the load, most migration objects stabilize after one or two runs, freeing up valuable time in the final weeks.
- Issue ownership becomes clear and resolution is faster: Late in a project, failed loads often trigger debates about responsibility: is the issue caused by source data, mapping logic, or SAP configuration? With a structured preparation layer, data-related issues are handled upstream, while SAP Data Migration Cockpit remains focused on execution. This clarity helps teams route problems quickly and avoid unnecessary escalation.
- Changes between test cycles are easier to understand and explain: Near cutover, even small data changes can have unexpected effects. When preparation is centralized and traceable, teams can see exactly what changed between runs and why a load behaved differently. This transparency is critical when decisions must be made quickly and with limited tolerance for uncertainty.
- Cutover readiness becomes visible and defensible: Instead of relying solely on recent successful loads as a readiness signal, teams can point to concrete preparation and validation results. This makes it easier to communicate status to project managers and business stakeholders, as well as to explain remaining risks in a clear, credible way.
Why this matters most near cutover
Cutover is the point at which migration issues stop being theoretical and start affecting the business. There is little room left for trial and error, and every failed load has a cascading impact on timelines, resources, and confidence. Projects that address data problems only during SAP Data Migration Cockpit execution often enter this phase in a reactive posture, relying on intense effort to compensate for late discovery.
When data issues are fixed before execution, the final phase of the migration feels fundamentally different. Migration Cockpit becomes a controlled execution step rather than a diagnostic tool, and cutover becomes a confirmation of readiness instead of a moment of discovery. This shift is what separates migrations that feel risky until the very end, from those that conclude with a calm, predictable transition into production.
When This Approach Makes Sense
After understanding why Migration Cockpit loads fail and how upstream preparation changes outcomes, the remaining question is whether this approach is the right fit for a given migration. The answer is less about technical preference and more about how much uncertainty the project can tolerate.
This approach makes sense when the following signals are present:
- Migration results vary between test cycles without a clear explanation: If the same object behaves differently from one load to the next and teams struggle to explain why, it usually indicates that preparation steps are not fully controlled. A structured preparation layer becomes valuable when consistency, not just correction, is the priority.
- Migration progress is difficult to explain to stakeholders: When readiness is assessed primarily by whether the last load passed, confidence tends to be fragile. This approach is useful when teams need clearer, more defensible indicators of progress and risk than execution results alone can provide.
- Troubleshooting depends heavily on tribal knowledge: If resolving migration issues requires specific individuals who “know how the data works,” the process is vulnerable. This approach helps when teams want to move from person-dependent problem solving to repeatable, transparent rules.
- Migration rehearsals feel riskier instead of more stable: Test cycles are meant to reduce uncertainty. When each rehearsal uncovers new problems rather than confirming readiness, it signals that issues are being discovered too late. Upstream preparation becomes valuable when rehearsals need to validate readiness, not reveal surprises.
- Decisions are delayed because data readiness is unclear: When teams hesitate to commit to timelines or cutover dates due to uncertainty around data quality, this approach provides a way to assess readiness independently of final execution.
In short, this approach makes sense when the cost of uncertainty outweighs the cost of additional structure. When migration teams need clearer signals, better explanations, and greater confidence in outcomes, preparing data before SAP Data Migration Cockpit execution becomes a practical way to regain control rather than an added layer of complexity.
Conclusion
When SAP Data Migration Cockpit loads fail repeatedly, the issue is rarely the tool itself. Migration Cockpit is doing exactly what it was designed to do: enforce SAP’s rules at the time of execution. The real problem is that unresolved data issues are being discovered too late, when time is short and tolerance for rework is low.
Shifting data preparation upstream changes that dynamic. When data is standardized, validated, and stabilized before it reaches SAP Data Migration Cockpit, execution becomes predictable rather than exploratory. Migration Cockpit turns into a confirmation step instead of a diagnostic one, and cutover becomes a managed transition rather than a moment of discovery.
If Migration Cockpit loads keep failing, don’t wait for another test cycle to reveal the next issue. DataLark helps teams fix data problems before execution by preparing and validating migration data upstream, so SAP Data Migration Cockpit can run as intended. See how DataLark fits into your migration approach and reduces rework, uncertainty, and risk before cutover.